切换主题
Hibernate 6 简介
版本 6.3.1.最终版
目录
[toc]
前言
Hibernate 6 是对世界上最流行且功能丰富的 ORM 解决方案的重大重新设计。重新设计几乎涉及 Hibernate 的每个子系统,包括 API、映射注释和查询语言。这个新的 Hibernate 更强大、更健壮、类型更安全。
有了如此多的改进,很难概括这项工作的意义。但以下一般主题很突出。休眠6:
- 最终利用过去十年关系数据库的进步,更新查询语言以支持现代 SQL 方言中的大量新结构,
- 在不同的数据库中表现出更加一致的行为,极大地提高了可移植性,并从与方言无关的代码中生成更高质量的 DDL,
- 通过在访问数据库之前更严格地验证查询来改进错误报告,
- 提高了 O/R 映射注释的类型安全性,澄清了 API、SPI 和内部实现的分离,并修复了一些长期存在的架构缺陷,
- 删除或弃用旧版 API,为未来的发展奠定基础,以及
- 更好地利用 Javadoc,为开发人员提供更多信息。
Hibernate 6 和 Hibernate Reactive 现在是 Quarkus 3 的核心组件,Quarkus 3 是 Java 云原生开发最令人兴奋的新环境,并且 Hibernate 仍然是几乎每个主要 Java 框架或服务器的持久性解决方案选择。
不幸的是,Hibernate 6 中的更改已经废弃了书籍、博客文章和 stackoverflow 上提供的有关 Hibernate 的大部分信息。
本指南是对当前功能集和建议用法的最新高级讨论。它并不试图涵盖所有功能,应与其他文档结合使用:
- Hibernate 广泛的Javadoc,
- Hibernate 查询语言指南,以及
- Hibernate用户指南。
| Hibernate 用户指南包含 Hibernate 大多数方面的详细讨论。但要涵盖的信息如此之多,可读性很难实现,因此作为参考最有用。如有必要,我们将提供用户指南相关部分的链接。 | |
|---|---|
1. 简介
Hibernate 通常被描述为一个库,可以轻松地将 Java 类映射到关系数据库表。但这种表述并没有充分体现关系数据本身所发挥的核心作用。所以更好的描述可能是:
Hibernate 使关系数据以****自然且类型安全的形式对用 Java 编写的程序可见,
- 可以轻松编写复杂的查询并处理其结果,
- 让程序轻松地将内存中的更改与数据库同步,尊重事务的 ACID 属性,以及
- 允许在编写基本持久性逻辑后进行性能优化。
这里关系数据是焦点,还有类型安全的重要性。对象/关系映射(ORM)的目标是消除脆弱和非类型安全的代码,并使大型程序从长远来看更易于维护。
ORM 使开发人员无需手动编写繁琐、重复且脆弱的代码来将对象图展平为数据库表,并从平面 SQL 查询结果集重建对象图,从而消除了持久性带来的痛苦。更好的是,在编写了基本的持久性逻辑之后,ORM 使以后调整性能变得更加容易。
| 一个长期存在的问题是:我应该使用 ORM 还是纯 SQL?答案通常是:两者都使用。JPA 和 Hibernate 被设计为与手写 SQL 结合使用。您会看到,大多数具有重要数据访问逻辑的程序至少会在某些地方受益于 ORM 的使用。但是,如果 Hibernate 使事情变得更加困难,对于某些特别棘手的数据访问逻辑,唯一明智的做法就是使用更适合该问题的东西!仅仅因为您使用 Hibernate 来实现持久性并不意味着您必须将它用于所有事情。 | |
|---|---|
开发人员经常询问 Hibernate 和 JPA 之间的关系,因此让我们简单回顾一下历史。
1.1. Hibernate 和 JPA
Hibernate 是Java(现在的Jakarta)持久性 API或 JPA背后的灵感来源,并且包含该规范最新版本的完整实现。
Hibernate 和 JPA 的早期历史
Hibernate 项目始于 2001 年,当时 Gavin King 对 EJB 2 中的 Entity Beans 的挫败感爆发了。它很快超越了其他开源和商业竞争者,成为最流行的 Java 持久性解决方案,与Christian Bauer 合着的*《Hibernate in Action 》一书是一本有影响力的畅销书。*
2004 年,Gavin 和 Christian 加入了一家名为 JBoss 的小型初创公司,其他早期 Hibernate 贡献者很快也加入了进来:Max Rydahl Andersen、Emmanuel Bernard、Steve Ebersole 和 Sanne Grinovero。
不久之后,Gavin 加入了 EJB 3 专家组,并说服该组弃用 Entity Beans,转而采用模仿 Hibernate 的全新持久性 API。后来,TopLink 团队的成员也参与进来,Java Persistence API 在 Linda Demichiel 的领导下,主要是 Sun、JBoss、Oracle 和 Sybase 之间的协作而发展起来。
在这二十年里,许多人才为 Hibernate 的发展做出了贡献。我们都特别感谢史蒂夫,自从加文退后专注于其他工作以来,他领导了该项目多年。
我们可以从三个基本元素的角度来思考 Hibernate API:
- JPA 定义的 API 的实现,最重要的是接口
EntityManagerFactory和 的实现EntityManager,以及 JPA 定义的 O/R 映射注释的实现, - 一个*本机 API,*公开全套可用功能,以接口为中心
SessionFactory,扩展了EntityManagerFactory、 、Session、 扩展了EntityManager、 和 - 一组映射注释,增强了 JPA 定义的 O/R 映射注释,并且可以与 JPA 定义的接口或本机 API 一起使用。
Hibernate 还为框架和库提供了一系列 SPI,用于扩展或与 Hibernate 集成,但我们对这里的任何东西都不感兴趣。
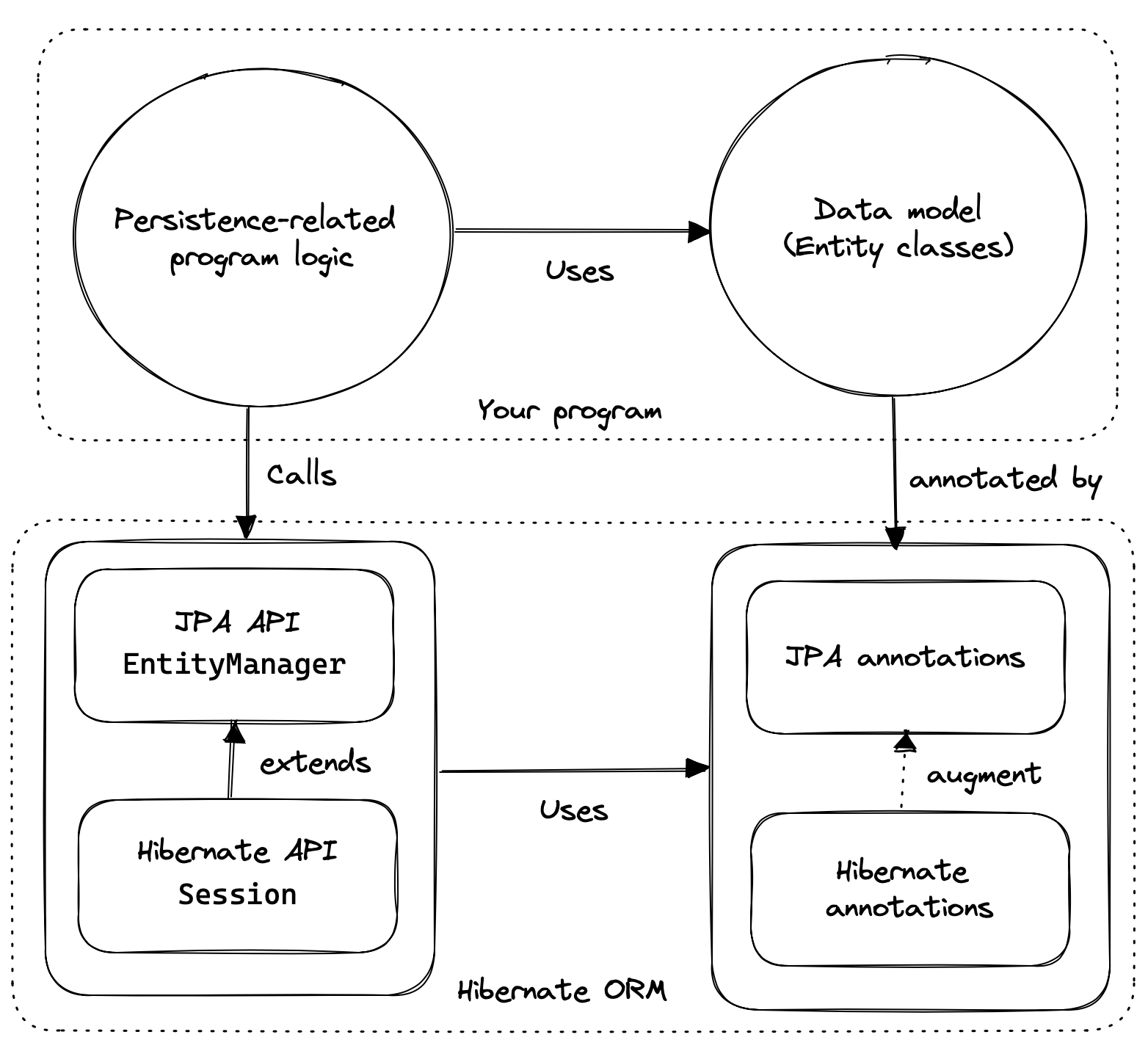
作为应用程序开发人员,您必须决定是否:
- 用
Session和SessionFactory或来编写你的程序 - 通过在合理的情况下,根据
EntityManager和编写代码EntityManagerFactory,仅在必要时回退到本机 API,最大限度地提高对 JPA 其他实现的可移植性。
无论选择哪条路径,大多数时候您都将使用 JPA 定义的映射注释,而 Hibernate 定义的注释则用于解决更高级的映射问题。
| 您可能想知道是否可以仅使用JPA 定义的 API 来开发应用程序,事实上,原则上这是可能的。JPA 是一个很好的基线,它真正解决了对象/关系映射问题的基础知识。但如果没有本机 API 和扩展映射注释,您将无法享受 Hibernate 的大部分功能。 | |
|---|---|
由于 Hibernate 在 JPA 之前就已经存在,并且 JPA 是在 Hibernate 的基础上建模的,因此不幸的是,标准 API 和本机 API 之间的命名存在一些竞争和重复。例如:
| 休眠 | 日本PA |
|---|---|
org.hibernate.annotations.CascadeType | javax.persistence.CascadeType |
org.hibernate.FlushMode | javax.persistence.FlushModeType |
org.hibernate.annotations.FetchMode | javax.persistence.FetchType |
org.hibernate.query.Query | javax.persistence.Query |
org.hibernate.Cache | javax.persistence.Cache |
@org.hibernate.annotations.NamedQuery | @javax.persistence.NamedQuery |
@org.hibernate.annotations.Cache | @javax.persistence.Cacheable |
通常,Hibernate 原生 API 会提供 JPA 中缺少的一些额外功能,因此这并不完全是一个缺陷。但这是需要注意的事情。
1.2. 使用 Hibernate 编写 Java 代码
如果您对 Hibernate 和 JPA 完全陌生,您可能已经想知道与持久性相关的代码是如何构造的。
通常,我们与持久性相关的代码分为两层:
- Java 数据模型的表示形式,采用一组带注释的实体类的形式,以及
- 大量与 Hibernate API 交互的函数,以执行与各种事务相关的持久性操作。
第一部分,即数据或“域”模型,通常更容易编写,但出色且非常干净的工作将强烈影响第二部分的成功。
大多数人将域模型实现为一组我们过去所说的“普通旧 Java 对象”,即简单的 Java 类,不直接依赖于技术基础设施,也不依赖于处理请求处理、事务管理的应用程序逻辑,通信,或与数据库的交互。
花点时间编写此代码,并尝试生成一个尽可能合理地接近关系数据模型的 Java 模型。当真正不需要时,避免使用奇异或高级的映射功能。如果有丝毫疑问,请优先使用@ManyToOnewith来映射外键关系,而不是更复杂的关联映射。@OneToMany(mappedBy=…) | |
|---|---|
代码的第二部分要正确执行要困难得多。该代码必须:
- 管理事务和会话,
- 通过 Hibernate 会话与数据库交互,
- 获取并准备 UI 所需的数据,以及
- 处理故障。
| 事务和会话管理以及从某些类型的故障中恢复的责任最好在某种框架代码中处理。 | |
|---|---|
我们很快就会回到这个棘手的问题,即应该如何组织这种持久性逻辑,以及它应该如何适应系统的其余部分。
1.3. 你好,Hibernate
在我们深入了解之前,我们将快速介绍一个基本的示例程序,如果您尚未将 Hibernate 集成到您的项目中,它将帮助您入门。
我们从一个简单的 gradle 构建文件开始:
build.gradle
plugins {
id 'java'
}
group = 'org.example'
version = '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
// the GOAT ORM
implementation 'org.hibernate.orm:hibernate-core:6.3.0.Final'
// Hibernate Validator
implementation 'org.hibernate.validator:hibernate-validator:8.0.0.Final'
implementation 'org.glassfish:jakarta.el:4.0.2'
// Agroal connection pool
implementation 'org.hibernate.orm:hibernate-agroal:6.3.0.Final'
implementation 'io.agroal:agroal-pool:2.1'
// logging via Log4j
implementation 'org.apache.logging.log4j:log4j-core:2.20.0'
// JPA Metamodel Generator
annotationProcessor 'org.hibernate.orm:hibernate-jpamodelgen:6.3.0.Final'
// Compile-time checking for HQL
//implementation 'org.hibernate:query-validator:2.0-SNAPSHOT'
//annotationProcessor 'org.hibernate:query-validator:2.0-SNAPSHOT'
// H2 database
runtimeOnly 'com.h2database:h2:2.1.214'
}只有第一个依赖项是运行 Hibernate所必需的。
接下来,我们将为 log4j 添加日志配置文件:log4j2.properties
properties
rootLogger.level = info
rootLogger.appenderRefs = console
rootLogger.appenderRef.console.ref = console
logger.hibernate.name = org.hibernate.SQL
logger.hibernate.level = info
appender.console.name = console
appender.console.type = Console
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %highlight{[%p]} %m%n现在我们需要一些 Java 代码。我们从实体类开始:Book.java
java
package org.hibernate.example;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import jakarta.validation.constraints.NotNull;
@Entity
class Book {
@Id
String isbn;
@NotNull
String title;
Book() {}
Book(String isbn, String title) {
this.isbn = isbn;
this.title = title;
}
}最后,让我们看看配置和实例化 Hibernate 并要求其持久化和查询实体的代码。如果现在这毫无意义,请不要担心。本简介的任务就是让这一切变得清晰。Main.java
java
package org.hibernate.example;
import org.hibernate.cfg.Configuration;
import static java.lang.Boolean.TRUE;
import static java.lang.System.out;
import static org.hibernate.cfg.AvailableSettings.*;
public class Main {
public static void main(String[] args) {
var sessionFactory = new Configuration()
.addAnnotatedClass(Book.class)
// use H2 in-memory database
.setProperty(URL, "jdbc:h2:mem:db1")
.setProperty(USER, "sa")
.setProperty(PASS, "")
// use Agroal connection pool
.setProperty("hibernate.agroal.maxSize", "20")
// display SQL in console
.setProperty(SHOW_SQL, TRUE.toString())
.setProperty(FORMAT_SQL, TRUE.toString())
.setProperty(HIGHLIGHT_SQL, TRUE.toString())
.buildSessionFactory();
// export the inferred database schema
sessionFactory.getSchemaManager().exportMappedObjects(true);
// persist an entity
sessionFactory.inTransaction(session -> {
session.persist(new Book("9781932394153", "Hibernate in Action"));
});
// query data using HQL
sessionFactory.inSession(session -> {
out.println(session.createSelectionQuery("select isbn||': '||title from Book").getSingleResult());
});
// query data using criteria API
sessionFactory.inSession(session -> {
var builder = sessionFactory.getCriteriaBuilder();
var query = builder.createQuery(String.class);
var book = query.from(Book.class);
query.select(builder.concat(builder.concat(book.get(Book_.isbn), builder.literal(": ")),
book.get(Book_.title)));
out.println(session.createSelectionQuery(query).getSingleResult());
});
}
}这里我们使用了 Hibernate 的原生 API。我们可以使用 JPA 标准 API 来实现同样的目的。
1.4. 你好,JPA
如果我们限制自己使用 JPA 标准 API,则需要使用 XML 来配置 Hibernate。META-INF/persistence.xml
xml
<persistence xmlns="https://jakarta.ee/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/persistence https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="3.0">
<persistence-unit name="example">
<class>org.hibernate.example.Book</class>
<properties>
<!-- H2 in-memory database -->
<property name="jakarta.persistence.jdbc.url"
value="jdbc:h2:mem:db1"/>
<!-- Credentials -->
<property name="jakarta.persistence.jdbc.user"
value="sa"/>
<property name="jakarta.persistence.jdbc.password"
value=""/>
<!-- Agroal connection pool -->
<property name="hibernate.agroal.maxSize"
value="20"/>
<!-- display SQL in console -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.highlight_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>请注意,我们的build.gradle和log4j2.properties文件未更改。
我们的实体类也与之前没有变化。
不幸的是,JPA 没有提供inSession()方法,因此我们必须自己实现会话和事务管理。我们可以将该逻辑放入我们自己的inSession()函数中,这样我们就不必为每笔交易重复它。同样,您现在不需要理解任何代码。
Main.java(JPA版)
package org.hibernate.example;
import jakarta.persistence.EntityManager;
import jakarta.persistence.EntityManagerFactory;
import java.util.Map;
import java.util.function.Consumer;
import static jakarta.persistence.Persistence.createEntityManagerFactory;
import static java.lang.System.out;
import static org.hibernate.cfg.AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION;
import static org.hibernate.tool.schema.Action.CREATE;
public class Main {
public static void main(String[] args) {
var factory = createEntityManagerFactory("example",
// export the inferred database schema
Map.of(JAKARTA_HBM2DDL_DATABASE_ACTION, CREATE));
// persist an entity
inSession(factory, entityManager -> {
entityManager.persist(new Book("9781932394153", "Hibernate in Action"));
});
// query data using HQL
inSession(factory, entityManager -> {
out.println(entityManager.createQuery("select isbn||': '||title from Book").getSingleResult());
});
// query data using criteria API
inSession(factory, entityManager -> {
var builder = factory.getCriteriaBuilder();
var query = builder.createQuery(String.class);
var book = query.from(Book.class);
query.select(builder.concat(builder.concat(book.get(Book_.isbn), builder.literal(": ")),
book.get(Book_.title)));
out.println(entityManager.createQuery(query).getSingleResult());
});
}
// do some work in a session, performing correct transaction management
static void inSession(EntityManagerFactory factory, Consumer<EntityManager> work) {
var entityManager = factory.createEntityManager();
var transaction = entityManager.getTransaction();
try {
transaction.begin();
work.accept(entityManager);
transaction.commit();
}
catch (Exception e) {
if (transaction.isActive()) transaction.rollback();
throw e;
}
finally {
entityManager.close();
}
}
}在实践中,我们从不直接从方法访问数据库main()。那么现在我们来谈谈如何在实际系统中组织持久化逻辑。本章的其余部分不是强制性的。如果您渴望了解有关 Hibernate 本身的更多详细信息,非常欢迎您直接跳到下一章,稍后再回来。
1.5. 组织持久性逻辑
在真实的程序中,像上面所示的代码这样的持久性逻辑通常与其他类型的代码交织在一起,包括逻辑:
- 实施业务领域的规则,或
- 用于与用户交互。
因此,许多开发人员很快(在我们看来甚至太快了)寻求将持久性逻辑隔离到某种单独的架构层中的方法。我们现在要求你抑制这种冲动。
使用Hibernate最简单的方法是直接调用Sessionor EntityManager。如果您是 Hibernate 新手,那么包装 JPA 的框架只会让您的生活变得更加困难。 | |
|---|---|
我们更喜欢采用自下而上的方法来组织代码。我们喜欢开始考虑方法和功能,而不是架构层和容器管理的对象。为了说明我们提倡的代码组织方法,让我们考虑一个使用 HQL 或 SQL 查询数据库的服务。
我们可能会从这样的东西开始,即 UI 和持久性逻辑的混合:
@Path("/") @Produces("application/json")
public class BookResource {
@GET @Path("book/{isbn}")
public Book getBook(String isbn) {
var book = sessionFactory.fromTransaction(session -> session.find(Book.class, isbn));
return book == null ? Response.status(404).build() : book;
}
}事实上,我们也可能会以类似的方式结束——很难识别出上面的代码有什么具体错误,而且对于这样一个简单的情况,似乎很难证明通过引入额外的对象使这段代码变得更加复杂是合理的。
我们希望引起您注意的这段代码的一个非常好的方面是,会话和事务管理是由通用“框架”代码处理的,正如我们上面已经推荐的那样。在本例中,我们使用的fromTransaction()方法恰好内置于 Hibernate 中。但您可能更喜欢使用其他东西,例如:
- 在 Jakarta EE 或 Quarkus 等容器环境中,容器管理的事务和容器管理的持久性上下文,或者
- 你自己写的东西。
重要的是,像createEntityManager()和那样的调用getTransaction().begin()不属于常规程序逻辑,因为正确处理错误既棘手又乏味。
现在让我们考虑一个稍微复杂的情况。
@Path("/") @Produces("application/json")
public class BookResource {
private static final RESULTS_PER_PAGE = 20;
@GET @Path("books/{titlePattern}/{page:\\d+}")
public List<Book> findBooks(String titlePattern, int page) {
var books = sessionFactory.fromTransaction(session -> {
return session.createSelectionQuery("from Book where title like ?1 order by title", Book.class)
.setParameter(1, titlePattern)
.setPage(Page.page(RESULTS_PER_PAGE, page))
.getResultList();
});
return books.isEmpty() ? Response.status(404).build() : books;
}
}这很好,如果您希望将代码保留为上面显示的样子,我们不会抱怨。但有一件事我们也许可以改进。我们喜欢具有单一职责的超短方法,并且看起来有机会在这里介绍一种方法。让我们用我们最喜欢的东西来编写代码,即提取方法重构。我们获得:
static List<Book> findBooksByTitleWithPagination(Session session,
String titlePattern, Page page) {
return session.createSelectionQuery("from Book where title like ?1 order by title", Book.class)
.setParameter(1, titlePattern)
.setPage(page)
.getResultList();
}这是一个查询方法的示例,该方法接受 HQL 或 SQL 查询参数的参数,并执行查询,将其结果返回给调用者。这就是它的全部作用;它不编排额外的程序逻辑,也不执行事务或会话管理。
最好使用注释指定查询字符串,以便 Hibernate 可以在启动时(即创建时,而不是首次执行查询时@NamedQuery验证查询) 。SessionFactory事实上,由于我们在Gradle 构建中包含了元模型生成器,因此甚至可以在编译时验证查询。
我们需要一个地方来放置注释,所以让我们将查询方法移动到一个新类:
@CheckHQL // validate named queries at compile time
@NamedQuery(name="findBooksByTitle",
query="from Book where title like :title order by title")
class Queries {
static List<Book> findBooksByTitleWithPagination(Session session,
String titlePattern, Page page) {
return session.createNamedQuery("findBooksByTitle", Book.class)
.setParameter("title", titlePattern)
.setPage(page)
.getResultList();
}
}EntityManager请注意,我们的查询方法不会尝试向客户端隐藏。事实上,客户端代码负责向查询方法提供EntityManageror 。Session这是我们整个方法的一个非常独特的特征。
客户端代码可以:
- 通过调用
EntityManageror获得or ,如我们上面所见,或者,Session``inTransaction()``fromTransaction() - 在具有容器管理事务的环境中,它可能通过依赖项注入来获取它。
无论哪种情况,编排工作单元的代码通常只是直接调用Sessionor EntityManager,如有必要,将其传递给辅助方法(例如我们的查询方法)。
@GET
@Path("books/{titlePattern}")
public List<Book> findBooks(String titlePattern) {
var books = sessionFactory.fromTransaction(session ->
Queries.findBooksByTitleWithPagination(session, titlePattern,
Page.page(RESULTS_PER_PAGE, page));
return books.isEmpty() ? Response.status(404).build() : books;
}您可能会认为我们的查询方法看起来有点样板。也许确实如此,但我们更担心它不是很类型安全。事实上,多年来,缺乏对 HQL 查询和将参数绑定到查询参数的代码的编译时检查是我们对 Hibernate 感到不适的第一个原因。
幸运的是,现在这两个问题都有一个解决方案:作为 Hibernate 6.3 的孵化功能,我们现在提供让元模型生成器为您填充此类查询方法的实现的可能性。此功能是本简介的一整章的主题,因此现在我们只给您留下一个简单的示例。
假设我们简化Queries为以下内容:
interface Queries {
@HQL("where title like :title order by title")
List<Book> findBooksByTitleWithPagination(String title, Page page);
}@HQL然后,元模型生成器会自动生成名为 的类中注释的方法的实现Queries_。我们可以像调用手写版本一样调用它:
@GET
@Path("books/{titlePattern}")
public List<Book> findBooks(String titlePattern) {
var books = sessionFactory.fromTransaction(session ->
Queries_.findBooksByTitleWithPagination(session, titlePattern,
Page.page(RESULTS_PER_PAGE, page));
return books.isEmpty() ? Response.status(404).build() : books;
}在这种情况下,消除的代码量非常小。真正的价值在于提高类型安全性。现在,我们发现编译时将参数分配给查询参数时出现的错误。
| 至此,我们确信您对这个想法充满了怀疑。确实如此。我们很乐意在这里回答您的反对意见,但这将使我们偏离正轨。所以我们要求你暂时把这些想法收起来。我们保证,当我们稍后正确解决这个主题时,它会变得有意义。并且,之后,如果您仍然不喜欢这种方法,请理解它是完全可选的。没有人会到你家来强迫你接受它。 | |
|---|---|
现在我们已经大致了解了持久性逻辑可能是什么样子,很自然地会问我们应该如何测试我们的代码。
1.6. 测试持久性逻辑
当我们为持久性逻辑编写测试时,我们将需要:
- 一个数据库,与
- 由我们的持久实体映射的模式实例,以及
- 一组测试数据,在每次测试开始时处于明确定义的状态。
似乎很明显,我们应该针对将在生产中使用的相同数据库系统进行测试,并且实际上,我们当然应该至少对此配置进行*一些测试。*但另一方面,执行 I/O 的测试比不执行 I/O 的测试慢得多,并且大多数数据库无法设置为进程内运行。
因此,由于使用 Hibernate 6 编写的大多数持久性逻辑在数据库之间具有极强的可移植性,因此针对内存中 Java 数据库进行测试通常很有意义。(我们推荐H2 。)
| 如果我们的持久性代码使用本机 SQL,或者如果它使用悲观锁等并发管理功能,那么我们确实需要小心。 | |
|---|---|
无论我们是针对真实数据库进行测试,还是针对内存中的 Java 数据库进行测试,我们都需要在测试套件开始时导出模式。我们通常在创建 HibernateSessionFactory或 JPA时执行此操作EntityManager,因此传统上我们为此使用配置属性。
JPA 标准属性是jakarta.persistence.schema-generation.database.action. 例如,如果我们使用ConfigurationHibernate 配置,我们可以这样写:
configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION,
Action.SPEC_ACTION_DROP_AND_CREATE);或者,在 Hibernate 6 中,我们可以使用新的SchemaManagerAPI 来导出模式,就像我们上面所做的那样。
sessionFactory.getSchemaManager().exportMappedObjects(true);由于在许多数据库上执行 DDL 语句非常慢,因此我们不想在每次测试之前都执行此操作。相反,为了确保每个测试都以处于明确定义状态的测试数据开始,我们需要在每个测试之前做两件事:
- 清理之前测试留下的任何混乱,然后
- 重新初始化测试数据。
我们可以使用SchemaManager.
sessionFactory.getSchemaManager().truncateMappedObjects();截断表后,我们可能需要初始化测试数据。我们可以在SQL脚本中指定测试数据,例如:
/导入.sql
insert into Books (isbn, title) values ('9781932394153', 'Hibernate in Action')
insert into Books (isbn, title) values ('9781932394887', 'Java Persistence with Hibernate')
insert into Books (isbn, title) values ('9781617290459', 'Java Persistence with Hibernate, Second Edition')如果我们将此文件命名为import.sql,并将其放置在根类路径中,这就是我们需要做的。
否则,我们需要在配置属性 jakarta.persistence.sql-load-script-source中指定该文件。如果我们使用ConfigurationHibernate 配置,我们可以这样写:
configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_LOAD_SCRIPT_SOURCE,
"/org/example/test-data.sql");SQL脚本每次exportMappedObjects()或被truncateMappedObjects()调用时都会被执行。
测试可能会留下另一种混乱:二级缓存中的缓存数据。我们建议对大多数类型的测试禁用Hibernate 的二级缓存。或者,如果二级缓存没有禁用,那么在每次测试之前我们应该调用:sessionFactory.getCache().evictAllRegions(); | |
|---|---|
现在,假设您已遵循我们的建议,并编写了实体和查询方法来最大程度地减少对“基础设施”的依赖,即对 JPA 和 Hibernate 以外的库、框架、容器管理对象,甚至是对某些库的依赖。您自己的系统很难从头开始实例化。那么测试持久性逻辑现在就很简单了!
您需要:
- 引导 Hibernate 并创建一个
SessionFactoryorEntityManagerFactory和测试套件的开头(我们已经了解了如何做到这一点),以及 - 在每个方法中创建一个新的
Session或,例如使用 。EntityManager``@Test``inTransaction()
实际上,某些测试可能需要多次会话。但请注意不要泄漏不同测试之间的会话。
我们需要的另一个重要测试是根据实际数据库模式验证我们的O/R 映射注释。这又是模式管理工具的工作,或者:configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION, Action.ACTION_VALIDATE);或者:sessionFactory.getSchemaManager().validateMappedObjects();即使在生产中,当系统启动时,许多人也喜欢运行此“测试”。 | |
|---|---|
1.7. 架构和持久层
现在让我们考虑一种不同的代码组织方法,我们对此持怀疑态度。
| 在本节中,我们将向您提供我们的意见。如果您只对事实感兴趣,或者如果您不想阅读可能会破坏您当前持有的观点的内容,请随时直接跳到下一章。 | |
|---|---|
Hibernate 是一个与体系结构无关的库,而不是一个框架,因此可以与各种 Java 框架和容器轻松集成。与我们在生态系统中的地位一致,我们历来避免提供太多关于架构的建议。这是我们现在可能会后悔的做法,因为由此产生的真空已经被提倡架构、设计模式和额外框架的人们的建议所填充,我们怀疑这些建议使 Hibernate 使用起来不太愉快。 。
特别是,包装 JPA 的框架似乎增加了臃肿性,同时又减少了 Hibernate 努力提供的一些对数据访问的细粒度控制。这些框架没有公开 Hibernate 的完整功能集,因此程序被迫使用功能较弱的抽象。
我们之所以犹豫是否要挑战这种古板、教条式的传统智慧,只是因为担心不可避免地伴随着这种教条式的引诱,我们会被直立的烦恼所刺痛:
与数据库交互的代码属于单独的持久层。
我们缺乏勇气——也许甚至缺乏信念——来明确告诉你不要遵循这个建议。但我们确实要求您考虑任何架构层的样板成本,以及在您的系统环境中这种成本所带来的好处是否真的值得。
为了给这个讨论添加一些背景纹理,并且冒着我们的引言在如此早期阶段退化为咆哮的风险,我们将要求您在幽默地谈论更多关于古代历史的同时。
DAO 和存储库的史诗故事
回到 Java EE 4 的黑暗时代,在 Hibernate 标准化之前,以及随后 JPA 在 Java 企业开发中取得优势之前,手工编写由 Hibernate 处理的混乱的 JDBC 交互是很常见的。在那个可怕的时代,出现了一种我们称之为数据访问对象(DAO)的模式。DAO 为您提供了一个放置所有讨厌的 JDBC 代码的地方,从而使重要的程序逻辑更加清晰。
当 Hibernate 在 2001 年突然出现时,开发人员喜欢上了它。但 Hibernate 没有实现任何规范,许多人希望减少或至少本地化其项目逻辑对 Hibernate 的依赖。一个明显的解决方案是保留 DAO,但用对 Hibernate 的调用替换其中的 JDBC 代码Session。
我们对接下来发生的事情部分地责怪自己。
早在 2002 年和 2003 年,这看起来确实是一件相当合理的事情。事实上,我们通过推荐(或者至少不阻止)在Hibernate in Action中使用 DAO,为这种方法的流行做出了贡献。我们特此为这一错误以及花了太长时间才认识到这一错误表示歉意。
最终,一些人开始相信,他们的 DAO 保护了他们的程序,使其免于过分依赖 ORM,从而允许他们“换出”Hibernate,并用 JDBC 或其他东西替代它。事实上,这从来都不是真的——JDBC 的编程模型(与数据库的每次交互都是显式且同步的)与 Hibernate 中的有状态会话的编程模型(其中更新是隐式的)和 SQL 语句之间存在着很大的差异。都是异步执行的。
但随后,Java 持久性的整个格局在 2006 年 4 月发生了变化,当时 JPA 1.0 的最终草案获得了批准。Java 现在有了执行 ORM 的标准方法,以及标准 API 的多个高质量实现。这是 DAO 的终结,对吗?
嗯,不。事实并非如此。DAO 被重新命名为“存储库”,并继续作为 JPA 的前端享受僵尸来世。但它们真的发挥了作用,还是只是不必要的额外复杂性和臃肿?额外的间接层会使堆栈跟踪更难读取并且代码更难调试?
我们深思熟虑的观点是,它们大多只是臃肿。JPAEntityManager是一个“存储库”,它是一个标准存储库,具有明确定义的规范,由整天思考持久性的人们编写。如果这些存储库框架提供了任何实际有用的东西——而且不是明显的脚射——除了所提供的东西之外,我们几十年前EntityManager就已经将它添加到了。EntityManager
最终,我们不确定您是否需要一个单独的持久层。至少考虑一下EntityManager直接从业务逻辑调用的可能性。
我们已经可以听到你对我们的异端邪说发出嘶嘶声。但在关上笔记本电脑的盖子并去拿大蒜和干草叉之前,请花几个小时来权衡我们的建议。
好的,所以,看,如果这让您感觉更好,一种查看方法EntityManager是将其视为适用于系统中每个实体的单个通用“存储库”。从这个角度来看,JPA就是你的持久层。并且没有什么充分的理由将这个抽象包装在第二个不太通用的抽象中。
即使在适合使用不同持久层的情况下,DAO 风格的存储库也不是分解方程的最正确方法:
- 大多数重要的查询都会涉及多个实体,因此这样的查询属于哪个存储库通常非常模糊,
- 大多数查询都非常特定于程序逻辑的特定片段,并且不会在系统中的不同位置重用,并且
- 存储库的各种操作很少交互或共享共同的内部实现细节。
事实上,存储库本质上表现出非常低的内聚性。如果每个存储库都有多个实现,那么存储库对象层可能有意义,但实际上几乎没有人这样做。这是因为他们与客户的耦合度非常高,并且具有非常大的 API 接口。相反,只有具有非常狭窄的API 的层才可以轻松替换。
| 有些人确实使用模拟存储库进行测试,但我们真的很难看到其中的任何价值。如果我们不想针对真实数据库运行测试,通常很容易通过针对内存 Java 数据库(如 H2)运行测试来“模拟”数据库本身。这在 Hibernate 6 中比在旧版本的 Hibernate 中效果更好,因为 HQL 现在在平台之间更加可移植。 | |
|---|---|
唷,我们继续吧。
1.8. 概述
现在是时候开始真正理解我们之前看到的代码了。
本简介将指导您完成开发使用 Hibernate 进行持久化的程序所涉及的基本任务:
SessionFactory配置和引导 Hibernate,并获取或的实例EntityManagerFactory,- 编写域模型,即一组实体类,它们代表程序中的持久类型,并映射到数据库的表,
- 当模型映射到预先存在的关系模式时自定义这些映射,
- 使用
Session或EntityManager执行查询数据库并返回实体实例的操作,或更新数据库中保存的数据的操作, - 使用 Hibernate Metamodel Generator 来提高编译时类型安全性,
- 使用 Hibernate 查询语言 (HQL) 或本机 SQL 编写复杂查询,最后
- 调整数据访问逻辑的性能。
当然,我们将从这个列表的顶部开始,从最不有趣的主题:配置。
2. 配置和引导
我们很乐意缩短这一部分。不幸的是,有几种不同的方法来配置和引导 Hibernate,我们将不得不详细描述其中至少两种。
获取Hibernate实例的四种基本方式如下表所示:
使用标准的JPA定义的XML,以及操作Persistence.createEntityManagerFactory() | 通常在 JPA 实现之间的可移植性很重要时选择。 |
|---|---|
使用Configuration类来构造一个SessionFactory | 当 JPA 实现之间的可移植性并不重要时,此选项速度更快,增加了一些灵活性并节省了类型转换。 |
使用中定义的更复杂的 APIorg.hibernate.boot | 此选项主要由框架集成商使用,不属于本文档的讨论范围。 |
通过让容器负责引导过程并注入SessionFactory或EntityManagerFactory | 用于 WildFly 或 Quarkus 等容器环境。 |
这里我们将重点关注前两个选项。
在容器中休眠
实际上,最后一个选项非常流行,因为每个主要的 Java 应用程序服务器和微服务框架都内置了对 Hibernate 的支持。EntityManager此类容器环境通常还具有自动管理或的生命周期Session及其与容器管理事务的关联的功能。
要了解如何在此类容器环境中配置 Hibernate,您需要参考所选容器的文档。对于 Quarkus,这里是相关文档。
如果您在容器环境之外使用 Hibernate,则需要:
- 包含 Hibernate ORM 本身以及适当的 JDBC 驱动程序作为项目的依赖项,以及
- 通过指定配置属性,使用有关数据库的信息配置 Hibernate。
2.1. 将 Hibernate 包含在您的项目构建中
首先,将以下依赖项添加到您的项目中:
org.hibernate.orm:hibernate-core:{版本}{version}您正在使用的 Hibernate 版本在哪里?
您还需要为数据库添加 JDBC 驱动程序的依赖项。
| 数据库 | 驱动程序依赖 |
|---|---|
| PostgreSQL 或 CockroachDB | org.postgresql:postgresql:{version} |
| MySQL 或 TiDB | com.mysql:mysql-connector-j:{version} |
| 玛丽亚数据库 | org.mariadb.jdbc:mariadb-java-client:{version} |
| 数据库2 | com.ibm.db2:jcc:{version} |
| SQL服务器 | com.microsoft.sqlserver:mssql-jdbc:${version} |
| 甲骨文 | com.oracle.database.jdbc:ojdbc11:${version} |
| 氢2 | com.h2database:h2:{version} |
| HSQL数据库 | org.hsqldb:hsqldb:{version} |
{version}适用于您的数据库的最新版本的 JDBC 驱动程序在哪里?
2.2. 可选依赖项
您还可以选择添加以下任何附加功能:
| 可选功能 | 依赖关系 |
|---|---|
| SLF4J日志记录实现 | org.apache.logging.log4j:log4j-core 或者org.slf4j:slf4j-jdk14 |
| JDBC 连接池,例如Agroal | org.hibernate.orm:hibernate-agroal 和io.agroal:agroal-pool |
| Hibernate Metamodel Generator,特别是当您使用 JPA 条件查询 API 时 | org.hibernate.orm:hibernate-jpamodelgen |
| 查询验证器,用于 HQL 的编译时检查 | org.hibernate:query-validator |
| Hibernate Validator , Bean Validation的实现 | org.hibernate.validator:hibernate-validator 和org.glassfish:jakarta.el |
| 通过 JCache 和EHCache支持本地二级缓存 | org.hibernate.orm:hibernate-jcache 和org.ehcache:ehcache |
| 通过 JCache 和Caffeine支持本地二级缓存 | org.hibernate.orm:hibernate-jcache 和com.github.ben-manes.caffeine:jcache |
| 通过Infinispan提供分布式二级缓存支持 | org.infinispan:infinispan-hibernate-cache-v60 |
| 用于处理 JSON 数据类型的 JSON 序列化库,例如Jackson或Yasson | com.fasterxml.jackson.core:jackson-databind 或者org.eclipse:yasson |
| 休眠空间 | org.hibernate.orm:hibernate-spatial |
| Envers,用于审计历史数据 | org.hibernate.orm:hibernate-envers |
如果您想使用字段级延迟获取,您还可以将 Hibernate字节码增强器添加到 Gradle 构建中。
2.3. 使用 JPA XML 进行配置
坚持 JPA 标准方法,我们将提供一个名为 的文件persistence.xml,我们通常将其放置在持久性存档META-INF的目录中,即包含实体类的文件或目录的目录中。.jar
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="2.0">
<persistence-unit name="org.hibernate.example">
<class>org.hibernate.example.Book</class>
<class>org.hibernate.example.Author</class>
<properties>
<!-- PostgreSQL -->
<property name="jakarta.persistence.jdbc.url"
value="jdbc:postgresql://localhost/example"/>
<!-- Credentials -->
<property name="jakarta.persistence.jdbc.user"
value="gavin"/>
<property name="jakarta.persistence.jdbc.password"
value="hibernate"/>
<!-- Automatic schema export -->
<property name="jakarta.persistence.schema-generation.database.action"
value="drop-and-create"/>
<!-- SQL statement logging -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.highlight_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>该<persistence-unit>元素定义了一个命名的持久单元,即:
- 关联实体类型的集合,以及
- 一组默认配置设置,可以在运行时增强或覆盖。
每个<class>元素指定实体类的完全限定名称。
扫描实体类
在某些容器环境中,例如在任何 EE 容器中,这些<class>元素是不必要的,因为容器将扫描存档中的带注释的类,并自动识别任何带注释的类@Entity。
每个<property>元素指定一个配置属性及其值。注意:
- 命名空间中的配置属性
jakarta.persistence是 JPA 规范定义的标准属性,并且 - 命名空间中的属性
hibernate是 Hibernate 特有的。
EntityManagerFactory我们可以通过致电获取Persistence.createEntityManagerFactory():
EntityManagerFactory entityManagerFactory =
Persistence.createEntityManagerFactory("org.hibernate.example");如有必要,我们可以覆盖中指定的配置属性persistence.xml:
EntityManagerFactory entityManagerFactory =
Persistence.createEntityManagerFactory("org.hibernate.example",
Map.of(AvailableSettings.JAKARTA_JDBC_PASSWORD, password));2.4. 使用 Hibernate API 进行配置
或者,古老的类Configuration允许在 Java 代码中配置 Hibernate 实例。
SessionFactory sessionFactory =
new Configuration()
.addAnnotatedClass(Book.class)
.addAnnotatedClass(Author.class)
// PostgreSQL
.setProperty(AvailableSettings.JAKARTA_JDBC_URL, "jdbc:postgresql://localhost/example")
// Credentials
.setProperty(AvailableSettings.JAKARTA_JDBC_USER, user)
.setProperty(AvailableSettings.JAKARTA_JDBC_PASSWORD, password)
// Automatic schema export
.setProperty(AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION,
Action.SPEC_ACTION_DROP_AND_CREATE)
// SQL statement logging
.setProperty(AvailableSettings.SHOW_SQL, TRUE.toString())
.setProperty(AvailableSettings.FORMAT_SQL, TRUE.toString())
.setProperty(AvailableSettings.HIGHLIGHT_SQL, TRUE.toString())
// Create a new SessionFactory
.buildSessionFactory();Configuration自 Hibernate 的最早版本(1.0 之前)以来,该类几乎没有发生任何变化,因此它看起来并不是特别现代。另一方面,它非常易于使用,并公开了一些persistence.xml不支持的选项。
高级配置选项
实际上,该类Configuration只是一个非常简单的外观,用于包中定义的更现代、更强大(但更复杂)的 API org.hibernate.boot。如果您有非常高级的需求,例如,如果您正在编写框架或实现容器,则此 API 非常有用。您可以在用户指南和的包级文档中找到更多信息org.hibernate.boot。
2.5. 使用 Hibernate 属性文件进行配置
如果我们使用 Hibernate ConfigurationAPI,但不想将某些配置属性直接放入 Java 代码中,则可以在名为 的文件中指定它们,hibernate.properties并将该文件放在根类路径中。
# PostgreSQL
jakarta.persistence.jdbc.url=jdbc:postgresql://localhost/example
# Credentials
jakarta.persistence.jdbc.user=hibernate
jakarta.persistence.jdbc.password=zAh7mY$2MNshzAQ5
# SQL statement logging
hibernate.show_sql=true
hibernate.format_sql=true
hibernate.highlight_sql=true2.6。基本配置设置
该类枚举AvailableSettings了 Hibernate 理解的所有配置属性。
当然,我们不会在本章中介绍所有有用的配置设置。相反,我们将提及您开始时需要的设置,并稍后返回一些其他重要设置,特别是当我们谈论性能调整时。
| Hibernate 有太多——太多——开关和切换。请不要疯狂地摆弄这些设置;其中大多数很少需要,并且许多的存在只是为了提供与旧版本 Hibernate 的向后兼容性。除了极少数例外,这些设置中每一项的默认行为都是经过精心选择的,作为我们推荐的行为。 | |
|---|---|
您真正开始需要的属性是这三个:
| 配置属性名称 | 目的 |
|---|---|
jakarta.persistence.jdbc.url | 数据库的 JDBC URL |
jakarta.persistence.jdbc.user和jakarta.persistence.jdbc.password | 您的数据库凭据 |
在 Hibernate 6 中,您不需要指定hibernate.dialect. Dialect将自动为您确定正确的 Hibernate SQL 。指定此属性的唯一原因是您使用的是自定义的用户编写的Dialect类。同样,在使用受支持的数据库之一时,也不需要hibernate.connection.driver_class或不需要。jakarta.persistence.jdbc.driver | |
|---|---|
池化 JDBC 连接是一项极其重要的性能优化。您可以使用此属性设置 Hibernate 内置连接池的大小:
| 配置属性名称 | 目的 |
|---|---|
hibernate.connection.pool_size | 内置连接池的大小 |
| 默认情况下,Hibernate 使用简单的内置连接池。这个池并不适合在生产中使用,稍后,当我们讨论性能时,我们将看到如何选择更健壮的实现。 | |
|---|---|
或者,在容器环境中,您至少需要以下属性之一:
| 配置属性名称 | 目的 |
|---|---|
jakarta.persistence.transactionType | (可选,默认为JTA)确定事务管理是通过 JTA 还是资源本地事务。指定RESOURCE_LOCAL是否不应使用 JTA。 |
jakarta.persistence.jtaDataSource | JTA 数据源的 JNDI 名称 |
jakarta.persistence.nonJtaDataSource | 非 JTA 数据源的 JNDI 名称 |
在这种情况下,Hibernate 从容器管理的DataSource.
2.7. 自动模式导出
您可以让 Hibernate 根据您在 Java 代码中指定的映射注释推断您的数据库模式,并通过指定以下一个或多个配置属性在初始化时导出该模式:
| 配置属性名称 | 目的 |
|---|---|
jakarta.persistence.schema-generation.database.action | 如果drop-and-create,首先删除架构,然后导出表、序列和约束If create,导出表、序列和约束,而不尝试先删除它们如果create-drop,则删除架构并在启动时重新创建它此外,在关闭时SessionFactory删除架构SessionFactory如果,则在关闭drop时删除架构SessionFactory如果validate,验证数据库架构而不更改它如果update,则仅导出架构中缺少的内容 |
jakarta.persistence.create-database-schemas | (可选)如果true,自动创建模式和目录 |
jakarta.persistence.schema-generation.create-source | (可选)如果metadata-then-script或script-then-metadata,则在导出表和序列时执行附加 SQL 脚本 |
jakarta.persistence.schema-generation.create-script-source | (可选)要执行的SQL DDL脚本的名称 |
jakarta.persistence.sql-load-script-source | (可选)要执行的SQL DML脚本的名称 |
此功能对于测试非常有用。
使用测试或“参考”数据预初始化数据库的最简单方法是将 SQL 语句列表放置insert在名为 的文件中import.sql,并使用属性 指定该文件的路径jakarta.persistence.sql-load-script-source。我们已经看到了这种方法的一个示例,它比编写 Java 代码来实例化实体实例并调用persist()每个实体实例更干净。 | |
|---|---|
正如我们之前提到的,以编程方式控制模式导出也很有用。
APISchemaManager允许对架构导出进行编程控制:sessionFactory.getSchemaManager().exportMappedObjects(true);JPA 有一个更有限且不太符合人体工程学的 API:Persistence.generateSchema("org.hibernate.example", Map.of(JAKARTA_HBM2DDL_DATABASE_ACTION, CREATE)) | |
|---|---|
2.8. 记录生成的 SQL
要在生成的 SQL 发送到数据库时查看它,您有两种选择。
一种方法是将属性设置hibernate.show_sql为true,Hibernate 会将 SQL 直接记录到控制台。您可以通过启用格式设置或突出显示来使输出更具可读性。这些设置在对生成的 SQL 语句进行故障排除时确实很有帮助。
| 配置属性名称 | 目的 |
|---|---|
hibernate.show_sql | 如果true,则将 SQL 直接记录到控制台 |
hibernate.format_sql | 如果true,以多行缩进格式记录 SQL |
hibernate.highlight_sql | If true,通过 ANSI 转义码使用语法突出显示记录 SQL |
org.hibernate.SQL或者,您可以使用您首选的 SLF4J 日志记录实现为该类别启用调试级别日志记录。
例如,如果您使用 Log4J 2(如上面可选依赖项中所示),请将这些行添加到您的log4j2.properties文件中:
# SQL execution
logger.hibernate.name = org.hibernate.SQL
logger.hibernate.level = debug
# JDBC parameter binding
logger.jdbc-bind.name=org.hibernate.orm.jdbc.bind
logger.jdbc-bind.level=trace
# JDBC result set extraction
logger.jdbc-extract.name=org.hibernate.orm.jdbc.extract
logger.jdbc-extract.level=trace但通过这种方法,我们错过了漂亮的突出显示。
2.9. 最大限度地减少重复的映射信息
@Table以下属性对于最大限度地减少需要在注释中显式指定的信息量非常有用@Column,我们将在下面的对象/关系映射中讨论这些信息:
| 配置属性名称 | 目的 |
|---|---|
hibernate.default_schema | 未显式声明实体的默认模式名称 |
hibernate.default_catalog | 未显式声明实体的默认目录名称 |
hibernate.physical_naming_strategy | APhysicalNamingStrategy实施数据库命名标准 |
hibernate.implicit_naming_strategy | 指定ImplicitNamingStrategy当注释中未指定名称时应如何推断关系对象的“逻辑”名称 |
编写自己的PhysicalNamingStrategyand/orImplicitNamingStrategy是一种特别好的方法,可以减少实体类上注释的混乱,并实现数据库命名约定,因此我们认为您应该为任何重要的数据模型执行此操作。我们将在命名策略中详细讨论它们。 | |
|---|---|
2.10. SQL Server 中的国家化字符数据
默认情况下, SQL Server 的char和varchar类型不容纳 Unicode 数据。但 Java 字符串可以包含任何 Unicode 字符。因此,如果您使用 SQL Server,您可能需要强制 Hibernate 使用nchar和nvarchar列类型。
| 配置属性名称 | 目的 |
|---|---|
hibernate.use_nationalized_character_data | 使用ncharandnvarchar代替charandvarchar |
另一方面,如果只有某些列存储国有化数据,请使用@Nationalized注释来指示映射这些列的实体的字段。
或者,您可以将 SQL Server 配置为使用启用 UTF-8 的排序规则_UTF8。 | |
|---|---|
3. 实体
实体是一个 Java类,它表示关系数据库表中的数据。我们说实体映射或者映射到表。不太常见的是,一个实体可能会聚合来自多个表的数据,但我们稍后会讨论这一点。
实体具有映射到表的列的属性(属性或字段)。特别是,每个实体都必须有一个标识符或id,它映射到表的主键。id 允许我们将表的一行与 Java 类的实例唯一关联,至少在给定的持久性上下文中是如此。
稍后我们将探讨持久性上下文的想法。现在,将其视为 id 和实体实例之间的一对一映射。
Java 类的实例不能比它所属的虚拟机存活得更久。但我们可能会认为实体实例的生命周期超越了内存中的特定实例。通过向 Hibernate 提供其 id,只要关联的行存在于数据库中,我们就可以在新的持久性上下文中重新具体化该实例。因此,操作persist()和remove()可以被认为是划分实体生命周期的开始和结束,至少在持久性方面。
因此,id 代表实体的*持久身份,该身份比内存中的特定实例更长寿。*这是实体类本身与其属性值之间的一个重要区别 - 实体具有持久标识,以及与持久性相关的明确定义的生命周期,而表示其属性值之一的 a 或 却String没有List。
一个实体通常与其他实体有关联。通常,两个实体之间的关联映射到数据库表之一中的外键。一组相互关联的实体通常称为领域模型,尽管数据模型也是一个非常好的术语。
3.1. 实体类
实体必须:
- 成为非
final阶级, - 带有
private不带参数的非构造函数。
另一方面,实体类可以是具体的abstract,也可以是具体的,并且它可以有任意数量的附加构造函数。
实体类可以是static内部类。 | |
|---|---|
每个实体类都必须带有注释@Entity。
@Entity
class Book {
Book() {}
...
}或者,可以通过为类提供基于 XML 的映射来将类标识为实体类型。
使用 XML 映射实体
当使用基于 XML 的映射时,该<entity>元素用于声明实体类:
<entity-mappings>
<package>org.hibernate.example</package>
<entity class="Book">
<attributes> ... </attributes>
</entity>
...
</entity-mappings>由于orm.xmlJPA 规范定义的映射文件格式是在基于注释的映射的基础上紧密建模的,因此通常很容易在两个选项之间来回切换。
在本简介中,我们不会对基于 XML 的映射进行更多讨论,因为这不是我们首选的处理方式。
“动态”模型
我们喜欢将实体表示为类,因为类为我们提供了类型安全的数据模型。但 Hibernate 还能够将实体表示为 的非类型化实例java.util.Map。如果您好奇的话,用户指南中提供了信息。
对于一个重视类型安全的项目来说,这听起来一定是一个奇怪的功能。实际上,对于一种非常特殊的通用代码来说,这是一种有用的功能。例如,Hibernate Envers是一个出色的 Hibernate 实体审核/版本控制系统。Envers 使用映射来表示其数据的版本模型。
3.2. 访问类型
每个实体类都有一个默认的访问类型,可以是:
- 直接现场访问,或
- 财产准入。
Hibernate 自动根据属性级注释的位置确定访问类型。具体来说:
- 如果字段被注释
@Id,则使用字段访问,或者 - 如果 getter 方法被注释
@Id,则使用属性访问。
当 Hibernate 刚刚起步时,属性访问在 Hibernate 社区中相当流行。然而,如今,现场访问变得更加普遍。
可以使用@Access注释显式指定默认访问类型,但我们强烈建议不要这样做,因为它很丑陋而且没有必要。 | |
|---|---|
映射注释应保持一致:如果@Id注释一个字段,则其他映射注释也应应用于字段,或者,如果@Id注释 getter,则其他映射注释应应用于 getter。原则上可以@Access在属性级别使用显式注释来混合字段和属性访问。我们不建议这样做。 | |
|---|---|
类似 的实体类Book,不扩展任何其他实体类,称为根实体。每个根实体必须声明一个标识符属性。
3.3. 实体类继承
一个实体类可以是extend另一个实体类。
@Entity
class AudioBook extends Book {
AudioBook() {}
...
}子类实体继承其扩展的每个实体的每个持久属性。
根实体还可以扩展另一个类并从另一个类继承映射的属性。但在这种情况下,声明映射属性的类必须被注释@MappedSuperclass。
@MappedSuperclass
class Versioned {
...
}
@Entity
class Book extends Versioned {
...
}根实体类必须声明一个带注释的属性@Id,或者从 a 继承一个属性@MappedSuperclass。子类实体始终继承根实体的标识符属性。它可能不声明自己的@Id属性。
3.4. 标识符属性
标识符属性通常是一个字段:
@Entity
class Book {
Book() {}
@Id
Long id;
...
}但它可能是一个属性:
@Entity
class Book {
Book() {}
private Long id;
@Id
Long getId() { return id; }
void setId(Long id) { this.id = id; }
...
}标识符属性必须被注释@Id或@EmbeddedId。
标识符值可以是:
- 由应用程序分配,即由您的 Java 代码分配,或者
- 由 Hibernate 生成和分配。
我们将首先讨论第二个选项。
3.5. 生成的标识符
标识符通常是系统生成的,在这种情况下应该对其进行注释@GeneratedValue:
@Id @GeneratedValue
Long id;| 系统生成的标识符或代理键使发展或重构关系数据模型变得更加容易。如果您可以自由定义关系模式,我们建议使用代理键。另一方面,如果(更常见的是)您正在使用预先存在的数据库模式,则您可能没有选择。 | |
|---|---|
JPA 定义了以下生成 ids 的策略,通过 枚举GenerationType:
| 战略 | Java类型 | 执行 |
|---|---|---|
GenerationType.UUID | UUID或者String | 爪哇UUID |
GenerationType.IDENTITY | Long或者Integer | 标识列或自动增量列 |
GenerationType.SEQUENCE | Long或者Integer | 数据库序列 |
GenerationType.TABLE | Long或者Integer | 数据库表 |
GenerationType.AUTO | Long或者Integer | 根据数据库的标识符类型和功能选择SEQUENCE、TABLE、 或UUID |
例如,这个 UUID 是在 Java 代码中生成的:
@Id @GeneratedValue UUID id; // AUTO strategy selects UUID based on the field type此 id 映射到 SQL identity、auto_increment或bigserial列:
@Id @GeneratedValue(strategy=IDENTITY) Long id;The @SequenceGenerator and @TableGenerator annotations allow further control over SEQUENCE and TABLE generation respectively.
Consider this sequence generator:
@SequenceGenerator(name="bookSeq", sequenceName="seq_book", initialValue = 5, allocationSize=10)Values are generated using a database sequence defined as follows:
create sequence seq_book start with 5 increment by 10Notice that Hibernate doesn’t have to go to the database every time a new identifier is needed. Instead, a given process obtains a block of ids, of size allocationSize, and only needs to hit the database each time the block is exhausted. Of course, the downside is that generated identifiers are not contiguous.
If you let Hibernate export your database schema, the sequence definition will have the right start with and increment values. But if you’re working with a database schema managed outside Hibernate, make sure the initialValue and allocationSize members of @SequenceGenerator match the start with and increment specified in the DDL. | |
|---|---|
Any identifier attribute may now make use of the generator named bookSeq:
@Id
@GeneratedValue(strategy=SEQUENCE, generator="bookSeq") // reference to generator defined elsewhere
Long id;Actually, it’s extremely common to place the @SequenceGenerator annotation on the @Id attribute that makes use of it:
@Id
@GeneratedValue(strategy=SEQUENCE, generator="bookSeq") // reference to generator defined below
@SequenceGenerator(name="bookSeq", sequenceName="seq_book", initialValue = 5, allocationSize=10)
Long id;JPA id generators may be shared between entities. A @SequenceGenerator or @TableGenerator must have a name, and may be shared between multiple id attributes. This fits somewhat uncomfortably with the common practice of annotating the @Id attribute which makes use of the generator! | |
|---|---|
As you can see, JPA provides quite adequate support for the most common strategies for system-generated ids. However, the annotations themselves are a bit more intrusive than they should be, and there’s no well-defined way to extend this framework to support custom strategies for id generation. Nor may @GeneratedValue be used on a property not annotated @Id. Since custom id generation is a rather common requirement, Hibernate provides a very carefully-designed framework for user-defined Generators, which we’ll discuss in User-defined generators.
3.6. Natural keys as identifiers
Not every identifier attribute maps to a (system-generated) surrogate key. Primary keys which are meaningful to the user of the system are called natural keys.
When the primary key of a table is a natural key, we don’t annotate the identifier attribute @GeneratedValue, and it’s the responsibility of the application code to assign a value to the identifier attribute.
@Entity
class Book {
@Id
String isbn;
...
}Of particular interest are natural keys which comprise more than one database column, and such natural keys are called composite keys.
3.7. Composite identifiers
If your database uses composite keys, you’ll need more than one identifier attribute. There are two ways to map composite keys in JPA:
- using an
@IdClass, or - using an
@EmbeddedId.
Perhaps the most immediately-natural way to represent this in an entity class is with multiple fields annotated @Id, for example:
@Entity
@IdClass(BookId.class)
class Book {
Book() {}
@Id
String isbn;
@Id
int printing;
...
}But this approach comes with a problem: what object can we use to identify a Book and pass to methods like find() which accept an identifier?
The solution is to write a separate class with fields that match the identifier attributes of the entity. The @IdClass annotation of the Book entity identifies the id class to use for that entity:
class BookId {
String isbn;
int printing;
BookId() {}
BookId(String isbn, int printing) {
this.isbn = isbn;
this.printing = printing;
}
@Override
public boolean equals(Object other) {
if (other instanceof BookId) {
BookId bookId = (BookId) other;
return bookId.isbn.equals(isbn)
&& bookId.printing == printing;
}
else {
return false;
}
}
@Override
public int hashCode() {
return isbn.hashCode();
}
}Every id class should override equals() and hashCode().
This is not our preferred approach. Instead, we recommend that the BookId class be declared as an @Embeddable type:
@Embeddable
class BookId {
String isbn;
int printing;
BookId() {}
BookId(String isbn, int printing) {
this.isbn = isbn;
this.printing = printing;
}
...
}We’ll learn more about Embeddable objects below.
Now the entity class may reuse this definition using @EmbeddedId, and the @IdClass annotation is no longer required:
@Entity
class Book {
Book() {}
@EmbeddedId
BookId bookId;
...
}This second approach eliminates some duplicated code.
Either way, we may now use BookId to obtain instances of Book:
Book book = session.find(Book.class, new BookId(isbn, printing));3.8. Version attributes
An entity may have an attribute which is used by Hibernate for optimistic lock checking. A version attribute is usually of type Integer, Short, Long, LocalDateTime, OffsetDateTime, ZonedDateTime, or Instant.
@Version
LocalDateTime lastUpdated;Version attributes are automatically assigned by Hibernate when an entity is made persistent, and automatically incremented or updated each time the entity is updated.
If an entity doesn’t have a version number, which often happens when mapping legacy data, we can still do optimistic locking. The @OptimisticLocking annotation lets us specify that optimistic locks should be checked by validating the values of ALL fields, or only the DIRTY fields of the entity. And the @OptimisticLock annotation lets us selectively exclude certain fields from optimistic locking. | |
|---|---|
The @Id and @Version attributes we’ve already seen are just specialized examples of basic attributes.
3.9. Natural id attributes
Even when an entity has a surrogate key, it should always be possible to write down a combination of fields which uniquely identifies an instance of the entity, from the point of view of the user of the system. This combination of fields is its natural key. Above, we considered the case where the natural key coincides with the primary key. Here, the natural key is a second unique key of the entity, distinct from its surrogate primary key.
| If you can’t identify a natural key, it might be a sign that you need to think more carefully about some aspect of your data model. If an entity doesn’t have a meaningful unique key, then it’s impossible to say what event or object it represents in the "real world" outside your program. | |
|---|---|
Since it’s extremely common to retrieve an entity based on its natural key, Hibernate has a way to mark the attributes of the entity which make up its natural key. Each attribute must be annotated @NaturalId.
@Entity
class Book {
Book() {}
@Id @GeneratedValue
Long id; // the system-generated surrogate key
@NaturalId
String isbn; // belongs to the natural key
@NaturalId
int printing; // also belongs to the natural key
...
}Hibernate automatically generates a UNIQUE constraint on the columns mapped by the annotated fields.
Consider using the natural id attributes to implement equals() and hashCode(). | |
|---|---|
The payoff for doing this extra work, as we will see much later, is that we can take advantage of optimized natural id lookups that make use of the second-level cache.
Note that even when you’ve identified a natural key, we still recommend the use of a generated surrogate key in foreign keys, since this makes your data model much easier to change.
3.10. Basic attributes
A basic attribute of an entity is a field or property which maps to a single column of the associated database table. The JPA specification defines a quite limited set of basic types:
| Classification | Package | Types |
|---|---|---|
| Primitive types | boolean, int, double, etc | |
| Primitive wrappers | java.lang | Boolean, Integer, Double, etc |
| Strings | java.lang | String |
| Arbitrary-precision numeric types | java.math | BigInteger, BigDecimal |
| Date/time types | java.time | LocalDate, LocalTime, LocalDateTime, OffsetDateTime, Instant |
| Deprecated date/time types 💀 | java.util | Date, Calendar |
| Deprecated JDBC date/time types 💀 | java.sql | Date, Time, Timestamp |
| Binary and character arrays | byte[], char[] | |
| UUIDs | java.util | UUID |
| Enumerated types | Any enum | |
| Serializable types | Any type which implements java.io.Serializable |
We’re begging you to use types from the java.time package instead of anything which inherits java.util.Date. | |
|---|---|
| Serializing a Java object and storing its binary representation in the database is usually wrong. As we’ll soon see in Embeddable objects, Hibernate has much better ways to handle complex Java objects. | |
|---|---|
Hibernate slightly extends this list with the following types:
| Classification | Package | Types |
|---|---|---|
| Additional date/time types | java.time | Duration, ZoneId, ZoneOffset, Year, and even ZonedDateTime |
| JDBC LOB types | java.sql | Blob, Clob, NClob |
| Java class object | java.lang | Class |
| Miscellaneous types | java.util | Currency, URL, TimeZone |
The @Basic annotation explicitly specifies that an attribute is basic, but it’s often not needed, since attributes are assumed basic by default. On the other hand, if a non-primitively-typed attribute cannot be null, use of @Basic(optional=false) is highly recommended.
@Basic(optional=false) String firstName;
@Basic(optional=false) String lastName;
String middleName; // may be nullNote that primitively-typed attributes are inferred NOT NULL by default.
How to make a column not null in JPA
There are two standard ways to add a NOT NULL constraint to a mapped column in JPA:
- using
@Basic(optional=false), or - using
@Column(nullable=false).
You might wonder what the difference is.
Well, it’s perhaps not obvious to a casual user of the JPA annotations, but they actually come in two "layers":
- annotations like
@Entity,@Id, and@Basicbelong to the logical layer, the subject of the current chapter—they specify the semantics of your Java domain model, whereas - annotations like
@Tableand@Columnbelong to the mapping layer, the topic of the next chapter—they specify how elements of the domain model map to objects in the relational database.
Information may be inferred from the logical layer down to the mapping layer, but is never inferred in the opposite direction.
Now, the @Column annotation, to whom we’ll be properly introduced a bit later, belongs to the mapping layer, and so its nullable member only affects schema generation (resulting in a not null constraint in the generated DDL). On the other hand, the @Basic annotation belongs to the logical layer, and so an attribute marked optional=false is checked by Hibernate before it even writes an entity to the database. Note that:
optional=falseimpliesnullable=false, butnullable=falsedoes not implyoptional=false.
Therefore, we prefer @Basic(optional=false) to @Column(nullable=false).
But wait! An even better solution is to use the @NotNull annotation from Bean Validation. Just add Hibernate Validator to your project build, as described in Optional dependencies. | |
|---|---|
3.11. Enumerated types
We included Java enums on the list above. An enumerated type is considered a sort of basic type, but since most databases don’t have a native ENUM type, JPA provides a special @Enumerated annotation to specify how the enumerated values should be represented in the database:
- by default, an enum is stored as an integer, the value of its
ordinal()member, but - if the attribute is annotated
@Enumerated(STRING), it will be stored as a string, the value of itsname()member.
//here, an ORDINAL encoding makes sense
@Enumerated
@Basic(optional=false)
DayOfWeek dayOfWeek;
//but usually, a STRING encoding is better
@Enumerated(EnumType.STRING)
@Basic(optional=false)
Status status;In Hibernate 6, an enum annotated @Enumerated(STRING) is mapped to:
- a
VARCHARcolumn type with aCHECKconstraint on most databases, or - an
ENUMcolumn type on MySQL.
Any other enum is mapped to a TINYINT column with a CHECK constraint.
JPA picks the wrong default here. In most cases, storing an integer encoding of the enum value makes the relational data harder to interpret.Even considering DayOfWeek, the encoding to integers is ambiguous. If you check java.time.DayOfWeek, you’ll notice that SUNDAY is encoded as 6. But in the country I was born, SUNDAY is the first day of the week!So we prefer @Enumerated(STRING) for most enum attributes. | |
|---|---|
An interesting special case is PostgreSQL. Postgres supports named ENUM types, which must be declared using a DDL CREATE TYPE statement. Sadly, these ENUM types aren’t well-integrated with the language nor well-supported by the Postgres JDBC driver, so Hibernate doesn’t use them by default. But if you would like to use a named enumerated type on Postgres, just annotate your enum attribute like this:
@JdbcTypeCode(SqlTypes.NAMED_ENUM)
@Basic(optional=false)
Status status;The limited set of pre-defined basic attribute types can be stretched a bit further by supplying a converter.
3.12. Converters
A JPA AttributeConverter is responsible for:
- converting a given Java type to one of the types listed above, and/or
- perform any other sort of pre- and post-processing you might need to perform on a basic attribute value before writing and reading it to or from the database.
Converters substantially widen the set of attribute types that can be handled by JPA.
There are two ways to apply a converter:
- the
@Convertannotation applies anAttributeConverterto a particular entity attribute, or - the
@Converterannotation (or, alternatively, the@ConverterRegistrationannotation) registers anAttributeConverterfor automatic application to all attributes of a given type.
For example, the following converter will be automatically applied to any attribute of type BitSet, and takes care of persisting the BitSet to a column of type varbinary:
@Converter(autoApply = true)
public static class EnumSetConverter implements AttributeConverter<EnumSet<DayOfWeek>,Integer> {
@Override
public Integer convertToDatabaseColumn(EnumSet<DayOfWeek> enumSet) {
int encoded = 0;
var values = DayOfWeek.values();
for (int i = 0; i<values.length; i++) {
if (enumSet.contains(values[i])) {
encoded |= 1<<i;
}
}
return encoded;
}
@Override
public EnumSet<DayOfWeek> convertToEntityAttribute(Integer encoded) {
var set = EnumSet.noneOf(DayOfWeek.class);
var values = DayOfWeek.values();
for (int i = 0; i<values.length; i++) {
if (((1<<i) & encoded) != 0) {
set.add(values[i]);
}
}
return set;
}
}On the other hand, if we don’t set autoapply=true, then we must explicitly apply the converter using the @Convert annotation:
@Convert(converter = BitSetConverter.class)
@Basic(optional = false)
BitSet bitset;All this is nice, but it probably won’t surprise you that Hibernate goes beyond what is required by JPA.
3.13. Compositional basic types
Hibernate considers a "basic type" to be formed by the marriage of two objects:
- a
JavaType, which models the semantics of a certain Java class, and - a
JdbcType, representing a SQL type which is understood by JDBC.
When mapping a basic attribute, we may explicitly specify a JavaType, a JdbcType, or both.
JavaType
An instance of org.hibernate.type.descriptor.java.JavaType represents a particular Java class. It’s able to:
- compare instances of the class to determine if an attribute of that class type is dirty (modified),
- produce a useful hash code for an instance of the class,
- coerce values to other types, and, in particular,
- convert an instance of the class to one of several other equivalent Java representations at the request of its partner
JdbcType.
For example, IntegerJavaType knows how to convert an Integer or int value to the types Long, BigInteger, and String, among others.
We may explicitly specify a Java type using the @JavaType annotation, but for the built-in JavaTypes this is never necessary.
@JavaType(LongJavaType.class) // not needed, this is the default JavaType for long
long currentTimeMillis;For a user-written JavaType, the annotation is more useful:
@JavaType(BitSetJavaType.class)
BitSet bitSet;Alternatively, the @JavaTypeRegistration annotation may be used to register BitSetJavaType as the default JavaType for BitSet.
JdbcType
A org.hibernate.type.descriptor.jdbc.JdbcType is able to read and write a single Java type from and to JDBC.
For example, VarcharJdbcType takes care of:
- writing Java strings to JDBC
PreparedStatements by callingsetString(), and - reading Java strings from JDBC
ResultSets usinggetString().
By pairing LongJavaType with VarcharJdbcType in holy matrimony, we produce a basic type which maps Longs and primitive longss to the SQL type VARCHAR.
We may explicitly specify a JDBC type using the @JdbcType annotation.
@JdbcType(VarcharJdbcType.class)
long currentTimeMillis;Alternatively, we may specify a JDBC type code:
@JdbcTypeCode(Types.VARCHAR)
long currentTimeMillis;The @JdbcTypeRegistration annotation may be used to register a user-written JdbcType as the default for a given SQL type code.
JDBC types and JDBC type codes
The types defined by the JDBC specification are enumerated by the integer type codes in the class java.sql.Types. Each JDBC type is an abstraction of a commonly-available type in SQL. For example, Types.VARCHAR represents the SQL type VARCHAR (or VARCHAR2 on Oracle).
Since Hibernate understand more SQL types than JDBC, there’s an extended list of integer type codes in the class org.hibernate.type.SqlTypes. For example, SqlTypes.GEOMETRY represents the spatial data type GEOMETRY.
AttributeConverter
If a given JavaType doesn’t know how to convert its instances to the type required by its partner JdbcType, we must help it out by providing a JPA AttributeConverter to perform the conversion.
For example, to form a basic type using LongJavaType and TimestampJdbcType, we would provide an AttributeConverter<Long,Timestamp>.
@JdbcType(TimestampJdbcType.class)
@Convert(converter = LongToTimestampConverter.class)
long currentTimeMillis;Let’s abandon our analogy right here, before we start calling this basic type a "throuple".
3.14. Embeddable objects
An embeddable object is a Java class whose state maps to multiple columns of a table, but which doesn’t have its own persistent identity. That is, it’s a class with mapped attributes, but no @Id attribute.
An embeddable object can only be made persistent by assigning it to the attribute of an entity. Since the embeddable object does not have its own persistent identity, its lifecycle with respect to persistence is completely determined by the lifecycle of the entity to which it belongs.
An embeddable class must be annotated @Embeddable instead of @Entity.
@Embeddable
class Name {
@Basic(optional=false)
String firstName;
@Basic(optional=false)
String lastName;
String middleName;
Name() {}
Name(String firstName, String middleName, String lastName) {
this.firstName = firstName;
this.middleName = middleName;
this.lastName = lastName;
}
...
}An embeddable class must satisfy the same requirements that entity classes satisfy, with the exception that an embeddable class has no @Id attribute. In particular, it must have a constructor with no parameters.
Alternatively, an embeddable type may be defined as a Java record type:
@Embeddable
record Name(String firstName, String middleName, String lastName) {}In this case, the requirement for a constructor with no parameters is relaxed.
Unfortunately, as of May 2023, Java record types still cannot be used as @EmbeddedIds. | |
|---|---|
We may now use our Name class (or record) as the type of an entity attribute:
@Entity
class Author {
@Id @GeneratedValue
Long id;
Name name;
...
}Embeddable types can be nested. That is, an @Embeddable class may have an attribute whose type is itself a different @Embeddable class.
JPA provides an @Embedded annotation to identify an attribute of an entity that refers to an embeddable type. This annotation is completely optional, and so we don’t usually use it. | |
|---|---|
另一方面,对可嵌入类型的引用永远不是多态的。一个@Embeddable类F可以继承第二个@Embeddable类E,但 type 的属性E将始终引用该具体类的实例E,而不是 的实例F。
通常,可嵌入类型以“扁平”格式存储。它们的属性映射其父实体的表的列。稍后,在将可嵌入类型映射到 UDT 或 JSON 中,我们将看到几个不同的选项。
可嵌入类型的属性表示具有持久标识的 Java 对象与不具有持久标识的 Java 对象之间的关系。我们可以将其视为整体/部分关系。可嵌入对象属于实体,不能与其他实体实例共享。并且只要其父实体存在,它就存在。
接下来我们将讨论一种不同类型的关系:Java 对象之间的关系,每个对象都有自己独特的持久标识和持久生命周期。
3.15。协会
关联是实体之间的关系。我们通常根据关联的多样性对其进行分类。如果E和F都是实体类,那么:
- 一对一关联最多将一个唯一实例与的
E最多一个唯一实例相关联F, - 多对一关联将零个或多个 的实例
E与 的唯一实例相关联F,并且 - 多对多关联将零个或多个 的实例与零个或多个的
E实例相关F。
实体类之间的关联可以是:
- 单向,可从
E导航至F,但不能从F导航至E,或 - 双向,并且可以在任一方向上导航。
在此示例数据模型中,我们可以看到可能的关联类型:
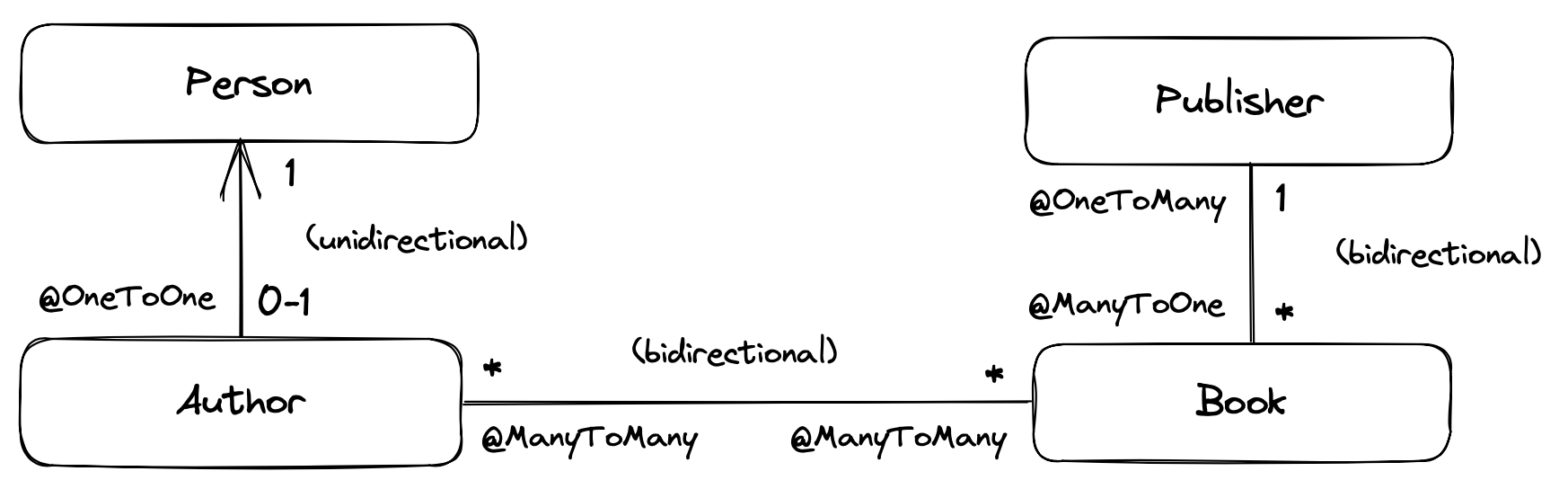
精明的观察者可能会注意到,我们以单向一对一关联的形式呈现的关系可以在 Java 中使用子类型合理地表示。这是很正常的。一对一关联是我们在完全标准化的关系模型中实现子类型的常用方式。这与JOINED 继承映射策略有关。 | |
|---|---|
映射关联有 3 个注释:@ManyToOne、@OneToMany和@ManyToMany。他们共享一些共同的注释成员:
| 成员 | 解释 | 默认值 |
|---|---|---|
cascade | 应级联到关联实体的持久化操作;CascadeTypes的列表 | {} |
fetch | 关联是急切 获取还是可以代理 | LAZY对于@OneToMany和@ManyToMany``EAGER为了@ManyToOne💀💀💀 |
targetEntity | 关联的实体类 | 由属性类型声明确定 |
optional | 对于@ManyToOneor@OneToOne关联,该关联是否可以null | true |
mappedBy | 对于双向关联,映射关联的关联实体的属性 | 默认情况下,假定关联是单向的 |
当我们考虑各种类型的关联映射时,我们将解释这些成员的作用。
让我们从最常见的关联多重性开始。
3.16。多对一
多对一关联是我们可以想象的最基本的关联类型。它完全自然地映射到数据库中的外键。域模型中的几乎所有关联都将采用这种形式。
| 稍后,我们将了解如何将多对一关联映射到关联表。 | |
|---|---|
该@ManyToOne注释标记了关联的“对一”一侧,因此单向多对一关联如下所示:
class Book {
@Id @GeneratedValue
Long id;
@ManyToOne(fetch=LAZY)
Publisher publisher;
...
}这里,Book表有一个外键列,保存关联的标识符Publisher。
JPA 的一个非常不幸的缺陷是@ManyToOne默认情况下会急切地获取关联。这几乎从来都不是我们想要的。几乎所有协会都应该是懒惰的。唯一有意义的情况是,如果我们认为在二级缓存中找到关联对象的可能性fetch=EAGER总是很高。每当情况并非如此时,请记住显式指定.fetch=LAZY | |
|---|---|
大多数时候,我们希望能够轻松地在两个方向上导航我们的关联。我们确实需要一种方法来获取给Publisher定的Book,但我们也希望能够获取Book属于给定发布者的所有 s 。
为了使这种关联是双向的,我们需要向类添加一个集合值属性Publisher,并对其进行注释@OneToMany。
Hibernate 需要在运行时代理未获取的关联。因此,多值端必须使用像Setor 这样的接口类型来声明,而不能使用像orList这样的具体类型。HashSet``ArrayList | |
|---|---|
为了清楚地表明这是一个双向关联,并重用实体中已指定的任何映射信息Book,我们必须使用mappedBy注释成员来引用回Book.publisher。
@Entity
class Publisher {
@Id @GeneratedValue
Long id;
@OneToMany(mappedBy="publisher")
Set<Book> books;
...
}该Publisher.books字段称为关联的无主端。
现在,我们非常讨厌mappedBy对关联拥有方的字符串类型引用。值得庆幸的是,元模型生成器为我们提供了一种使其类型更加安全的方法:
@OneToMany(mappedBy=Book_.PUBLISHER) // get used to doing it this way!
Set<Book> books;We’re going to use this approach for the rest of the Introduction.
To modify a bidirectional association, we must change the owning side.
Changes made to the unowned side of an association are never synchronized to the database. If we desire to change an association in the database, we must change it from the owning side. Here, we must set Book.publisher.In fact, it’s often necessary to change both sides of a bidirectional association. For example, if the collection Publisher.books was stored in the second-level cache, we must also modify the collection, to ensure that the second-level cache remains synchronized with the database. | |
|---|---|
That said, it’s not a hard requirement to update the unowned side, at least if you’re sure you know what you’re doing.
In principle Hibernate does allow you to have a unidirectional one-to-many, that is, a @OneToMany with no matching @ManyToOne on the other side. In practice, this mapping is unnatural, and just doesn’t work very well. Avoid it. | |
|---|---|
Here we’ve used Set as the type of the collection, but Hibernate also allows the use of List or Collection here, with almost no difference in semantics. In particular, the List may not contain duplicate elements, and its order will not be persistent.
@OneToMany(mappedBy=Book_.PUBLISHER)
Collection<Book> books;We’ll see how to map a collection with a persistent order much later.
Set, List, or Collection?
A one-to-many association mapped to a foreign key can never contain duplicate elements, so Set seems like the most semantically correct Java collection type to use here, and so that’s the conventional practice in the Hibernate community.
The catch associated with using a set is that we must carefully ensure that Book has a high-quality implementation of equals() and hashCode(). Now, that’s not necessarily a bad thing, since a quality equals() is independently useful.
But what if we used Collection or List instead? Then our code would be much less sensitive to how equals() and hashCode() were implemented.
In the past, we were perhaps too dogmatic in recommending the use of Set. Now? I guess we’re happy to let you guys decide. In hindsight, we could have done more to make clear that this was always a viable option.
3.17. One-to-one (first way)
The simplest sort of one-to-one association is almost exactly like a @ManyToOne association, except that it maps to a foreign key column with a UNIQUE constraint.
| Later, we’ll see how to map a one-to-one association to an association table. | |
|---|---|
A one-to-one association must be annotated @OneToOne:
@Entity
class Author {
@Id @GeneratedValue
Long id;
@OneToOne(optional=false, fetch=LAZY)
Person author;
...
}Here, the Author table has a foreign key column holding the identifier of the associated Publisher.
A one-to-one association often models a "type of" relationship. In our example, an Author is a type of Person. An alternative—and often more natural—way to represent "type of" relationships in Java is via entity class inheritance. | |
|---|---|
We can make this association bidirectional by adding a reference back to the Author in the Person entity:
@Entity
class Person {
@Id @GeneratedValue
Long id;
@OneToOne(mappedBy = Author_.PERSON)
Author author;
...
}Person.author is the unowned side, because it’s the side marked mappedBy.
Lazy fetching for one-to-one associations
Notice that we did not declare the unowned end of the association fetch=LAZY. That’s because:
- not every
Personhas an associatedAuthor, and - the foreign key is held in the table mapped by
Author, not in the table mapped byPerson.
Therefore, Hibernate can’t tell if the reference from Person to Author is null without fetching the associated Author.
On the other hand, if every Person was an Author, that is, if the association were non-optional, we would not have to consider the possibility of null references, and we would map it like this:
@OneToOne(optional=false, mappedBy = Author_.PERSON, fetch=LAZY)
Author author;This is not the only sort of one-to-one association.
3.18. One-to-one (second way)
An arguably more elegant way to represent such a relationship is to share a primary key between the two tables.
To use this approach, the Author class must be annotated like this:
@Entity
class Author {
@Id
Long id;
@OneToOne(optional=false, fetch=LAZY)
@MapsId
Person author;
...
}Notice that, compared with the previous mapping:
- the
@Idattribute is no longer a@GeneratedValueand, - instead, the
authorassociation is annotated@MapsId.
This lets Hibernate know that the association to Person is the source of primary key values for Author.
Here, there’s no extra foreign key column in the Author table, since the id column holds the identifier of Person. That is, the primary key of the Author table does double duty as the foreign key referring to the Person table.
The Person class doesn’t change. If the association is bidirectional, we annotate the unowned side @OneToOne(mappedBy = Author_.PERSON) just as before.
3.19. Many-to-many
A unidirectional many-to-many association is represented as a collection-valued attribute. It always maps to a separate association table in the database.
It tends to happen that a many-to-many association eventually turns out to be an entity in disguise.
Suppose we start with a nice clean many-to-many association between Author and Book. Later on, it’s quite likely that we’ll discover some additional information which comes attached to the association, so that the association table needs some extra columns.例如,假设我们需要报告每位作者对一本书的贡献百分比。该信息自然属于关联表。我们不能轻易地将其存储为 的属性Book,也不能将其存储为 的属性Author。当这种情况发生时,我们需要改变我们的Java模型,通常引入一个新的实体类来直接映射关联表。在我们的示例中,我们可以将此实体称为BookAuthorship,并且它@OneToMany与Author和Book以及contribution属性都有关联。@ManyToMany我们可以通过从一开始就避免使用权利来避免此类“发现”造成的破坏。使用中间实体来表示每个(或至少几乎每个)逻辑多对多关联几乎没有什么缺点。 | |
|---|---|
多对多关联必须注释@ManyToMany:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@ManyToMany
Set<Author> authors;
...
}如果关联是双向的,我们向 中添加一个看起来非常相似的属性Book,但是这次我们必须指定mappedBy以表明这是关联的无主端:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@ManyToMany(mappedBy=Author_.BOOKS)
Set<Author> authors;
...
}请记住,如果我们希望修改集合,我们必须更改拥有方。
我们再次使用Sets 来代表关联。和以前一样,我们可以选择使用Collectionor List。但在这种情况下,它确实对关联的语义产生了影响。
Collection表示为或 的多对多关联List可能包含重复元素。然而,和以前一样,元素的顺序不是持久的。也就是说,该收藏品是一个包,而不是一套。 | |
|---|---|
3.20。基本值和可嵌入对象的集合
我们现在已经看到了以下类型的实体属性:
| 实体属性的种类 | 参考种类 | 多重性 | 例子 |
|---|---|---|---|
| 基本类型的单值属性 | 非实体 | 最多一个 | @Basic String name |
| 可嵌入类型的单值属性 | 非实体 | 最多一个 | @Embedded Name name |
| 单值关联 | 实体 | 最多一个 | @ManyToOne Publisher publisher @OneToOne Person person |
| 多值关联 | 实体 | 零个或多个 | @OneToMany Set<Book> books @ManyToMany Set<Author> authors |
浏览这个分类法,您可能会问:Hibernate 是否具有基本类型或可嵌入类型的多值属性?
嗯,实际上,我们已经看到它确实如此,至少在两种特殊情况下是这样。首先,让我们回顾一下 JPA 将byte[]和char[]数组视为基本类型。Hibernate分别将byte[]或char[]数组持久化为VARBINARY或VARCHAR列。
但在本节中,我们真正关心的是这两种特殊情况以外的*情况。*那么,除了byte[]和 之外char[],Hibernate 是否还有基本类型或嵌入类型的多值属性呢?
答案再次是确实如此。事实上,有两种不同的方法可以通过映射来处理这样的集合:
- 到 SQL 类型的列
ARRAY(假设数据库有一个ARRAY类型),或者 - 到一个单独的表。
因此,我们可以通过以下方式扩展我们的分类:
| 实体属性的种类 | 参考种类 | 多重性 | 例子 |
|---|---|---|---|
byte[]和char[]数组 | 非实体 | 零个或多个 | byte[] image char[] text |
| 基本类型元素的集合 | 非实体 | 零个或多个 | @Array String[] names @ElementCollection Set<String> names |
| 可嵌入元素的集合 | 非实体 | 零个或多个 | @ElementCollection Set<Name> names |
这里实际上有两种新的映射:@Array映射和@ElementCollection映射。
| 这些类型的映射已被过度使用。在某些情况下,我们认为在实体类中使用基本类型值的集合是合适的。但这种情况很少见。几乎每个多值关系都应该映射到不同表之间的外键关联。并且几乎每个表都应该由实体类映射。我们将在接下来的两小节中介绍的功能,初学者使用的频率比专家使用的频率要高得多。因此,如果您是初学者,暂时远离这些功能会省去同样的麻烦。 | |
|---|---|
我们首先讨论@Array映射。
3.21。映射到 SQL 数组的集合
让我们考虑一个在一周中的某些日子重复的日历事件。我们可以在实体中将其表示为类型或Event的属性。由于此数组或列表的元素数量上限为 7,因此这是使用- 类型列的合理情况。很难看出将这个集合存储在单独的表中有多大价值。DayOfWeek[]``List<DayOfWeek>``ARRAY
学会不讨厌 SQL 数组
很长一段时间,我们认为数组是添加到关系模型中的一种奇怪而棘手的东西,但最近我们开始意识到这种观点过于封闭。事实上,我们可能选择将 SQL类型视为通用“元素”类型ARRAY的泛化。从这个角度来看,SQL 数组看起来相当有吸引力,至少对于某些问题来说是这样。如果我们可以轻松地映射到,为什么我们会回避映射到 呢?VARCHAR``VARBINARY``byte[]``VARBINARY(255)``DayOfWeek[]``TINYINT ARRAY[7]
不幸的是,JPA 没有定义映射 SQL 数组的标准方法,但我们可以在 Hibernate 中执行以下操作:
@Entity
class Event {
@Id @GeneratedValue
Long id;
...
@Array(length=7)
DayOfWeek[] daysOfWeek; // stored as a SQL ARRAY type
...
}注释@Array是可选的,但限制数据库分配给列的存储空间量很重要ARRAY。
现在要注意的问题是:并非每个数据库都有 SQLARRAY类型,有些数据库确实有ARRAY类型,但不允许将其用作列类型。特别是,DB2 和 SQL Server 都没有数组类型的列。在这些数据库上,Hibernate 会陷入更糟糕的境地:它使用 Java 序列化将数组编码为二进制表示形式,并将二进制流存储在列中VARBINARY。很明显,这太可怕了。您可以要求 Hibernate通过注释 attribute来做一些稍微@JdbcTypeCode(SqlTypes.JSON)不那么糟糕的事情,以便将数组序列化为 JSON 而不是二进制格式。但此时最好认输并使用 a@ElementCollection代替。 | |
|---|---|
或者,我们可以将此数组或列表存储在单独的表中。
3.22. 映射到单独表的集合
JPA确实定义了一种将集合映射到辅助表的标准方法:注释@ElementCollection。
@Entity
class Event {
@Id @GeneratedValue
Long id;
...
@ElementCollection
DayOfWeek[] daysOfWeek; // stored in a dedicated table
...
}实际上,我们不应该在这里使用数组,因为数组类型无法被代理,因此 JPA 规范甚至没有说它们是受支持的。相反,我们应该使用Set、List或Map。
@Entity
class Event {
@Id @GeneratedValue
Long id;
...
@ElementCollection
List<DayOfWeek> daysOfWeek; // stored in a dedicated table
...
}这里,每个集合元素都存储为辅助表的单独行。默认情况下,该表具有以下定义:
create table Event_daysOfWeek (
Event_id bigint not null,
daysOfWeek tinyint check (daysOfWeek between 0 and 6),
daysOfWeek_ORDER integer not null,
primary key (Event_id, daysOfWeek_ORDER)
)这很好,但它仍然是我们希望避免的映射。
@ElementCollection是我们最不喜欢的 JPA 功能之一。甚至注释的名称也很糟糕。上面的代码生成一个包含三列的表:表的外键Event,编码,TINYINT和enum``INTEGER对数组中元素的顺序进行编码。它没有代理主键,而是由外键Event和顺序列组成的复合键。当我们不可避免地发现需要向该表添加第四列时,我们的 Java 代码必须完全更改。最有可能的是,我们会意识到我们毕竟需要添加一个单独的实体。因此,面对我们的数据模型的微小变化,这种映射并不是很稳健。 | |
|---|---|
关于“元素集合”,我们还有很多话要说,但我们不会说出来,因为我们不想把枪交给你,让你用它来射脚。
3.23. 注释摘要
让我们停下来回忆一下到目前为止我们所遇到的注释。
| 注解 | 目的 | JPA标准 |
|---|---|---|
@Entity | 声明一个实体类 | ✔ |
@MappedSuperclass | 声明一个非实体类,其映射属性由实体继承 | ✔ |
@Embeddable | 声明可嵌入类型 | ✔ |
@IdClass | @Id声明具有多个属性的实体的标识符类 | ✔ |
| 注解 | 目的 | JPA标准 | |
|---|---|---|---|
@Id | 声明基本类型标识符属性 | ✔ | |
@Version | 声明版本属性 | ✔ | |
@Basic | 声明一个基本属性 | 默认 | ✔ |
@EmbeddedId | 声明可嵌入类型的标识符属性 | ✔ | |
@Embedded | 声明可嵌入类型的属性 | 推断 | ✔ |
@Enumerated | 声明一个enum-typed 属性并指定它的编码方式 | 推断 | ✔ |
@Array | 声明属性映射到 SQLARRAY并指定长度 | 推断 | ✖ |
@ElementCollection | 声明集合映射到专用表 | ✔ |
| Annotation | Purpose | JPA-standard |
|---|---|---|
@Converter | Register an AttributeConverter | ✔ |
@Convert | Apply a converter to an attribute | ✔ |
@JavaType | Explicitly specify an implementation of JavaType for a basic attribute | ✖ |
@JdbcType | Explicitly specify an implementation of JdbcType for a basic attribute | ✖ |
@JdbcTypeCode | Explicitly specify a JDBC type code used to determine the JdbcType for a basic attribute | ✖ |
@JavaTypeRegistration | Register a JavaType for a given Java type | ✖ |
@JdbcTypeRegistration | Register a JdbcType for a given JDBC type code | ✖ |
| Annotation | Purpose | JPA-standard |
|---|---|---|
@GeneratedValue | Specify that an identifier is system-generated | ✔ |
@SequenceGenerator | Define an id generated backed by on a database sequence | ✔ |
@TableGenerator | Define an id generated backed by a database table | ✔ |
@IdGeneratorType | Declare an annotation that associates a custom Generator with each @Id attribute it annotates | ✖ |
@ValueGenerationType | Declare an annotation that associates a custom Generator with each @Basic attribute it annotates | ✖ |
| Annotation | Purpose | JPA-standard |
|---|---|---|
@ManyToOne | Declare the single-valued side of a many-to-one association (the owning side) | ✔ |
@OneToMany | Declare the many-valued side of a many-to-one association (the unowned side) | ✔ |
@ManyToMany | Declare either side of a one-to-one association | ✔ |
@OneToOne | Declare either side of a one-to-one association | ✔ |
@MapsId | Declare that the owning side of a @OneToOne association maps the primary key column | ✔ |
Phew! That’s already a lot of annotations, and we have not even started with the annotations for O/R mapping!
3.24. equals() and hashCode()
Entity classes should override equals() and hashCode(), especially when associations are represented as sets.
People new to Hibernate or JPA are often confused by exactly which fields should be included in the hashCode(). And people with more experience often argue quite religiously that one or another approach is the only right way. The truth is, there’s no unique right way to do it, but there are some constraints. So please keep the following principles in mind:
- You should not include a mutable field in the hashcode, since that would require rehashing every collection containing the entity whenever the field is mutated.
- It’s not completely wrong to include a generated identifier (surrogate key) in the hashcode, but since the identifier is not generated until the entity instance is made persistent, you must take great care to not add it to any hashed collection before the identifier is generated. We therefore advise against including any database-generated field in the hashcode.
It’s OK to include any immutable, non-generated field in the hashcode.
We therefore recommend identifying a natural key for each entity, that is, a combination of fields that uniquely identifies an instance of the entity, from the perspective of the data model of the program. The natural key should correspond to a unique constraint on the database, and to the fields which are included in equals() and hashCode(). | |
|---|---|
In this example, the equals() and hashCode() methods agree with the @NaturalId annotation:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@NaturalId
@Basic(optional=false)
String isbn;
...
@Override
public boolean equals(Object other) {
return other instanceof Book
&& ((Book) other).isbn.equals(isbn);
}
@Override
public int hashCode() {
return isbn.hashCode();
}
}That said, an implementation of equals() and hashCode() based on the generated identifier of the entity can work if you’re careful.
4. Object/relational mapping
Given a domain model—that is, a collection of entity classes decorated with all the fancy annotations we just met in the previous chapter—Hibernate will happily go away and infer a complete relational schema, and even export it to your database if you ask politely.
The resulting schema will be entirely sane and reasonable, though if you look closely, you’ll find some flaws. For example, every VARCHAR column will have the same length, VARCHAR(255).
But the process I just described—which we call top down mapping—simply doesn’t fit the most common scenario for the use of O/R mapping. It’s only rarely that the Java classes precede the relational schema. Usually, we already have a relational schema, and we’re constructing our domain model around the schema. This is called bottom up mapping.
| Developers often refer to a pre-existing relational database as "legacy" data. This tends to conjure images of bad old "legacy apps" written in COBOL or something. But legacy data is valuable, and learning to work with it is important. | |
|---|---|
Especially when mapping bottom up, we often need to customize the inferred object/relational mappings. This is a somewhat tedious topic, and so we don’t want to spend too many words on it. Instead, we’ll quickly skim the most important mapping annotations.
Hibernate SQL case convention
Computers have had lowercase letters for rather a long time now. Most developers learned long ago that text written in MixedCase, camelCase, or even snake_case is easier to read than text written in SHOUTYCASE. This is just as true of SQL as it is of any other language.
Therefore, for over twenty years, the convention on the Hibernate project has been that:
- query language identifiers are written in
lowercase, - table names are written in
MixedCase, and - column names are written in
camelCase.
That is to say, we simply adopted Java’s excellent conventions and applied them to SQL.
Now, there’s no way we can force you to follow this convention, even if we wished to. Hell, you can easily write a PhysicalNamingStrategy which makes table and column names ALL UGLY AND SHOUTY LIKE THIS IF YOU PREFER. But, by default, it’s the convention Hibernate follows, and it’s frankly a pretty reasonable one.
4.1. Mapping entity inheritance hierarchies
In Entity class inheritance we saw that entity classes may exist within an inheritance hierarchy. There’s three basic strategies for mapping an entity hierarchy to relational tables. Let’s put them in a table, so we can more easily compare the points of difference between them.
| Strategy | Mapping | Polymorphic queries | Constraints | Normalization | When to use it |
|---|---|---|---|---|---|
SINGLE_TABLE | Map every class in the hierarchy to the same table, and uses the value of a discriminator column to determine which concrete class each row represents. | To retrieve instances of a given class, we only need to query the one table. | Attributes declared by subclasses map to columns without NOT NULL constraints. 💀Any association may have a FOREIGN KEY constraint. 🤓 | Subclass data is denormalized. 🧐 | Works well when subclasses declare few or no additional attributes. |
JOINED | Map every class in the hierarchy to a separate table, but each table only maps the attributes declared by the class itself.Optionally, a discriminator column may be used. | To retrieve instances of a given class, we must JOIN the table mapped by the class with:all tables mapped by its superclasses andall tables mapped by its subclasses. | Any attribute may map to a column with a NOT NULL constraint. 🤓Any association may have a FOREIGN KEY constraint. 🤓 | The tables are normalized. 🤓 | The best option when we care a lot about constraints and normalization. |
TABLE_PER_CLASS | Map every concrete class in the hierarchy to a separate table, but denormalize all inherited attributes into the table. | To retrieve instances of a given class, we must take a UNION over the table mapped by the class and the tables mapped by its subclasses. | Associations targeting a superclass cannot have a corresponding FOREIGN KEY constraint in the database. 💀💀Any attribute may map to a column with a NOT NULL constraint. 🤓 | Superclass data is denormalized. 🧐 | Not very popular.From a certain point of view, competes with @MappedSuperclass. |
The three mapping strategies are enumerated by InheritanceType. We specify an inheritance mapping strategy using the @Inheritance annotation.
For mappings with a discriminator column, we should:
- specify the discriminator column name and type by annotating the root entity
@DiscriminatorColumn, and - specify the values of this discriminator by annotating each entity in the hierarchy
@DiscriminatorValue.
For single table inheritance we always need a discriminator:
@Entity
@DiscriminatorColumn(discriminatorType=CHAR, name="kind")
@DiscriminatorValue('P')
class Person { ... }
@Entity
@DiscriminatorValue('A')
class Author { ... }We don’t need to explicitly specify @Inheritance(strategy=SINGLE_TABLE), since that’s the default.
For JOINED inheritance we don’t need a discriminator:
@Entity
@Inheritance(strategy=JOINED)
class Person { ... }
@Entity
class Author { ... }| However, we can add a discriminator column if we like, and in that case the generated SQL for polymorphic queries will be slightly simpler. | |
|---|---|
Similarly, for TABLE_PER_CLASS inheritance we have:
@Entity
@Inheritance(strategy=TABLE_PER_CLASS)
class Person { ... }
@Entity
class Author { ... }Hibernate doesn’t allow discriminator columns for TABLE_PER_CLASS inheritance mappings, since they would make no sense, and offer no advantage. | |
|---|---|
Notice that in this last case, a polymorphic association like:
@ManyToOne Person person;is a bad idea, since it’s impossible to create a foreign key constraint that targets both mapped tables.
4.2. Mapping to tables
The following annotations specify exactly how elements of the domain model map to tables of the relational model:
| Annotation | Purpose |
|---|---|
@Table | Map an entity class to its primary table |
@SecondaryTable | Define a secondary table for an entity class |
@JoinTable | Map a many-to-many or many-to-one association to its association table |
@CollectionTable | Map an @ElementCollection to its table |
The first two annotations are used to map an entity to its primary table and, optionally, one or more secondary tables.
4.3. Mapping entities to tables
By default, an entity maps to a single table, which may be specified using @Table:
@Entity
@Table(name="People")
class Person { ... }However, the @SecondaryTable annotation allows us to spread its attributes across multiple secondary tables.
@Entity
@Table(name="Books")
@SecondaryTable(name="Editions")
class Book { ... }The @Table annotation can do more than just specify a name:
| Annotation member | Purpose |
|---|---|
name | The name of the mapped table |
schema 💀 | The schema to which the table belongs |
catalog 💀 | The catalog to which the table belongs |
uniqueConstraints | One or more @UniqueConstraint annotations declaring multi-column unique constraints |
indexes | One or more @Index annotations each declaring an index |
It only makes sense to explicitly specify the schema in annotations if the domain model is spread across multiple schemas.Otherwise, it’s a bad idea to hardcode the schema (or catalog) in a @Table annotation. Instead:set the configuration property hibernate.default_schema (or hibernate.default_catalog), orsimply specify the schema in the JDBC connection URL. | |
|---|---|
The @SecondaryTable annotation is even more interesting:
| Annotation member | Purpose |
|---|---|
name | The name of the mapped table |
schema 💀 | The schema to which the table belongs |
catalog 💀 | The catalog to which the table belongs |
uniqueConstraints | One or more @UniqueConstraint annotations declaring multi-column unique constraints |
indexes | One or more @Index annotations each declaring an index |
pkJoinColumns | One or more @PrimaryKeyJoinColumn annotations, specifying primary key column mappings |
foreignKey | An @ForeignKey annotation specifying the name of the FOREIGN KEY constraint on the @PrimaryKeyJoinColumns |
Using @SecondaryTable on a subclass in a SINGLE_TABLE entity inheritance hierarchy gives us a sort of mix of SINGLE_TABLE with JOINED inheritance. | |
|---|---|
4.4. Mapping associations to tables
The @JoinTable annotation specifies an association table, that is, a table holding foreign keys of both associated entities. This annotation is usually used with @ManyToMany associations:
@Entity
class Book {
...
@ManyToMany
@JoinTable(name="BooksAuthors")
Set<Author> authors;
...
}But it’s even possible to use it to map a @ManyToOne or @OneToOne association to an association table.
@Entity
class Book {
...
@ManyToOne(fetch=LAZY)
@JoinTable(name="BookPublisher")
Publisher publisher;
...
}Here, there should be a UNIQUE constraint on one of the columns of the association table.
@Entity
class Author {
...
@OneToOne(optional=false, fetch=LAZY)
@JoinTable(name="AuthorPerson")
Person author;
...
}Here, there should be a UNIQUE constraint on both columns of the association table.
| Annotation member | Purpose |
|---|---|
name | The name of the mapped association table |
schema 💀 | The schema to which the table belongs |
catalog 💀 | The catalog to which the table belongs |
uniqueConstraints | One or more @UniqueConstraint annotations declaring multi-column unique constraints |
indexes | One or more @Index annotations each declaring an index |
joinColumns | One or more @JoinColumn annotations, specifying foreign key column mappings to the table of the owning side |
inverseJoinColumns | One or more @JoinColumn annotations, specifying foreign key column mappings to the table of the unowned side |
foreignKey | An @ForeignKey annotation specifying the name of the FOREIGN KEY constraint on the joinColumnss |
inverseForeignKey | An @ForeignKey annotation specifying the name of the FOREIGN KEY constraint on the inverseJoinColumnss |
To better understand these annotations, we must first discuss column mappings in general.
4.5. Mapping to columns
These annotations specify how elements of the domain model map to columns of tables in the relational model:
| Annotation | Purpose |
|---|---|
@Column | Map an attribute to a column |
@JoinColumn | Map an association to a foreign key column |
@PrimaryKeyJoinColumn | Map the primary key used to join a secondary table with its primary, or a subclass table in JOINED inheritance with its root class table |
@OrderColumn | Specifies a column that should be used to maintain the order of a List. |
@MapKeyColumn | Specified a column that should be used to persist the keys of a Map. |
We use the @Column annotation to map basic attributes.
4.6. Mapping basic attributes to columns
The @Column annotation is not only useful for specifying the column name.
| Annotation member | Purpose |
|---|---|
name | The name of the mapped column |
table | The name of the table to which this column belongs |
length | The length of a VARCHAR, CHAR, or VARBINARY column type |
precision | The decimal digits of precision of a FLOAT, DECIMAL, NUMERIC, or TIME, or TIMESTAMP column type |
scale | The scale of a DECIMAL or NUMERIC column type, the digits of precision that occur to the right of the decimal point |
unique | Whether the column has a UNIQUE constraint |
nullable | Whether the column has a NOT NULL constraint |
insertable | Whether the column should appear in generated SQL INSERT statements |
updatable | Whether the column should appear in generated SQL UPDATE statements |
columnDefinition 💀 | A DDL fragment that should be used to declare the column |
We no longer recommend the use of columnDefinition since it results in unportable DDL. Hibernate has much better ways to customize the generated DDL using techniques that result in portable behavior across different databases. | |
|---|---|
Here we see four different ways to use the @Column annotation:
@Entity
@Table(name="Books")
@SecondaryTable(name="Editions")
class Book {
@Id @GeneratedValue
@Column(name="bookId") // customize column name
Long id;
@Column(length=100, nullable=false) // declare column as VARCHAR(100) NOT NULL
String title;
@Column(length=17, unique=true, nullable=false) // declare column as VARCHAR(17) NOT NULL UNIQUE
String isbn;
@Column(table="Editions", updatable=false) // column belongs to the secondary table, and is never updated
int edition;
}We don’t use @Column to map associations.
4.7. Mapping associations to foreign key columns
The @JoinColumn annotation is used to customize a foreign key column.
| Annotation member | Purpose |
|---|---|
name | The name of the mapped foreign key column |
table | The name of the table to which this column belongs |
referencedColumnName | The name of the column to which the mapped foreign key column refers |
unique | Whether the column has a UNIQUE constraint |
nullable | Whether the column has a NOT NULL constraint |
insertable | Whether the column should appear in generated SQL INSERT statements |
updatable | Whether the column should appear in generated SQL UPDATE statements |
columnDefinition 💀 | A DDL fragment that should be used to declare the column |
foreignKey | A @ForeignKey annotation specifying the name of the FOREIGN KEY constraint |
A foreign key column doesn’t necessarily have to refer to the primary key of the referenced table. It’s quite acceptable for the foreign key to refer to any other unique key of the referenced entity, even to a unique key of a secondary table.
Here we see how to use @JoinColumn to define a @ManyToOne association mapping a foreign key column which refers to the @NaturalId of Book:
@Entity
@Table(name="Items")
class Item {
...
@ManyToOne(optional=false) // implies nullable=false
@JoinColumn(name = "bookIsbn", referencedColumnName = "isbn", // a reference to a non-PK column
foreignKey = @ForeignKey(name="ItemsToBooksBySsn")) // supply a name for the FK constraint
Book book;
...
}In case this is confusing:
bookIsbnis the name of the foreign key column in theItemstable,- it refers to a unique key
isbnin theBookstable, and - it has a foreign key constraint named
ItemsToBooksBySsn.
Note that the foreignKey member is completely optional and only affects DDL generation.
If you don’t supply an explicit name using @ForeignKey, Hibernate will generate a quite ugly name. The reason for this is that the maximum length of foreign key names on some databases is extremely constrained, and we need to avoid collisions. To be fair, this is perfectly fine if you’re only using the generated DDL for testing. | |
|---|---|
For composite foreign keys we might have multiple @JoinColumn annotations:
@Entity
@Table(name="Items")
class Item {
...
@ManyToOne(optional=false)
@JoinColumn(name = "bookIsbn", referencedColumnName = "isbn")
@JoinColumn(name = "bookPrinting", referencedColumnName = "printing")
Book book;
...
}If we need to specify the @ForeignKey, this starts to get a bit messy:
@Entity
@Table(name="Items")
class Item {
...
@ManyToOne(optional=false)
@JoinColumns(value = {@JoinColumn(name = "bookIsbn", referencedColumnName = "isbn"),
@JoinColumn(name = "bookPrinting", referencedColumnName = "printing")},
foreignKey = @ForeignKey(name="ItemsToBooksBySsn"))
Book book;
...
}For associations mapped to a @JoinTable, fetching the association requires two joins, and so we must declare the @JoinColumns inside the @JoinTable annotation:
@Entity
class Book {
@Id @GeneratedValue
Long id;
@ManyToMany
@JoinTable(joinColumns=@JoinColumn(name="bookId"),
inverseJoinColumns=@joinColumn(name="authorId"),
foreignKey=@ForeignKey(name="BooksToAuthors"))
Set<Author> authors;
...
}Again, the foreignKey member is optional.
4.8. Mapping primary key joins between tables
The @PrimaryKeyJoinColumn is a special-purpose annotation for mapping:
- the primary key column of a
@SecondaryTable—which is also a foreign key referencing the primary table, or - the primary key column of the primary table mapped by a subclass in a
JOINEDinheritance hierarchy—which is also a foreign key referencing the primary table mapped by the root entity.
| Annotation member | Purpose |
|---|---|
name | The name of the mapped foreign key column |
referencedColumnName | The name of the column to which the mapped foreign key column refers |
columnDefinition 💀 | A DDL fragment that should be used to declare the column |
foreignKey | A @ForeignKey annotation specifying the name of the FOREIGN KEY constraint |
When mapping a subclass table primary key, we place the @PrimaryKeyJoinColumn annotation on the entity class:
@Entity
@Table(name="People")
@Inheritance(strategy=JOINED)
class Person { ... }
@Entity
@Table(name="Authors")
@PrimaryKeyJoinColumn(name="personId") // the primary key of the Authors table
class Author { ... }But to map a secondary table primary key, the @PrimaryKeyJoinColumn annotation must occur inside the @SecondaryTable annotation:
@Entity
@Table(name="Books")
@SecondaryTable(name="Editions",
pkJoinColumns = @PrimaryKeyJoinColumn(name="bookId")) // the primary key of the Editions table
class Book {
@Id @GeneratedValue
@Column(name="bookId") // the name of the primary key of the Books table
Long id;
...
}4.9. Column lengths and adaptive column types
Hibernate automatically adjusts the column type used in generated DDL based on the column length specified by the @Column annotation. So we don’t usually need to explicitly specify that a column should be of type TEXT or CLOB—or worry about the parade of TINYTEXT, MEDIUMTEXT, TEXT, LONGTEXT types on MySQL—because Hibernate will automatically select one of those types if required to accommodate a string of the length we specify.
The constant values defined in the class Length are very helpful here:
| Constant | Value | Description |
|---|---|---|
DEFAULT | 255 | The default length of a VARCHAR or VARBINARY column when none is explicitly specified |
LONG | 32600 | The largest column length for a VARCHAR or VARBINARY that is allowed on every database Hibernate supports |
LONG16 | 32767 | The maximum length that can be represented using 16 bits (but this length is too large for a VARCHAR or VARBINARY column on for some database) |
LONG32 | 2147483647 | The maximum length for a Java string |
We can use these constants in the @Column annotation:
@Column(length=LONG)
String text;
@Column(length=LONG32)
byte[] binaryData;This is usually all you need to do to make use of large object types in Hibernate.
4.10. LOBs
JPA provides a @Lob annotation which specifies that a field should be persisted as a BLOB or CLOB.
Semantics of the @Lob annotation
What the spec actually says is that the field should be persisted
…as a large object to a database-supported large object type.
It’s quite unclear what this means, and the spec goes on to say that
…the treatment of the
Lobannotation is provider-dependent…
which doesn’t help much.
Hibernate interprets this annotation in what we think is the most reasonable way. In Hibernate, an attribute annotated @Lob will be written to JDBC using the setClob() or setBlob() method of PreparedStatement, and will be read from JDBC using the getClob() or getBlob() method of ResultSet.
Now, the use of these JDBC methods is usually unnecessary! JDBC drivers are perfectly capable of converting between String and CLOB or between byte[] and BLOB. So unless you specifically need to use these JDBC LOB APIs, you don’t need the @Lob annotation.
Instead, as we just saw in Column lengths and adaptive column types, all you need is to specify a large enough column length to accommodate the data you plan to write to that column.
Unfortunately, the driver for PostgreSQL doesn’t allow BYTEA or TEXT columns to be read via the JDBC LOB APIs.This limitation of the Postgres driver has resulted in a whole cottage industry of bloggers and stackoverflow question-answerers recommending convoluted ways to hack the Hibernate Dialect for Postgres to allow an attribute annotated @Lob to be written using setString() and read using getString().But simply removing the @Lob annotation has exactly the same effect.Conclusion:on PostgreSQL, @Lob always means the OID type,@Lob should never be used to map columns of type BYTEA or TEXT, andplease don’t believe everything you read on stackoverflow. | |
|---|---|
Finally, as an alternative, Hibernate lets you declare an attribute of type java.sql.Blob or java.sql.Clob.
@Entity
class Book {
...
Clob text;
Blob coverArt;
....
}The advantage is that a java.sql.Clob or java.sql.Blob can in principle index up to 263 characters or bytes, much more data than you can fit in a Java String or byte[] array (or in your computer).
To assign a value to these fields, we’ll need to use a LobHelper. We can get one from the Session:
LobHelper helper = session.getLobHelper();
book.text = helper.createClob(text);
book.coverArt = helper.createBlob(image);In principle, the Blob and Clob objects provide efficient ways to read or stream LOB data from the server.
Book book = session.find(Book.class, bookId);
String text = book.text.getSubString(1, textLength);
InputStream bytes = book.images.getBinaryStream();Of course, the behavior here depends very much on the JDBC driver, and so we really can’t promise that this is a sensible thing to do on your database.
4.11. Mapping embeddable types to UDTs or to JSON
There’s a couple of alternative ways to represent an embeddable type on the database side.
Embeddables as UDTs
First, a really nice option, at least in the case of Java record types, and for databases which support user-defined types (UDTs), is to define a UDT which represents the record type. Hibernate 6 makes this really easy. Just annotate the record type, or the attribute which holds a reference to it, with the new @Struct annotation:
@Embeddable
@Struct(name="PersonName")
record Name(String firstName, String middleName, String lastName) {}
@Entity
class Person {
...
Name name;
...
}This results in the following UDT:
create type PersonName as (firstName varchar(255), middleName varchar(255), lastName varchar(255))And the name column of the Author table will have the type PersonName.
Embeddables to JSON
A second option that’s available is to map the embeddable type to a JSON (or JSONB) column. Now, this isn’t something we would exactly recommend if you’re defining a data model from scratch, but it’s at least useful for mapping pre-existing tables with JSON-typed columns. Since embeddable types are nestable, we can map some JSON formats this way, and even query JSON properties using HQL.
| At this time, JSON arrays are not supported! | |
|---|---|
To map an attribute of embeddable type to JSON, we must annotate the attribute @JdbcTypeCode(SqlTypes.JSON), instead of annotating the embeddable type. But the embeddable type Name should still be annotated @Embeddable if we want to query its attributes using HQL.
@Embeddable
record Name(String firstName, String middleName, String lastName) {}
@Entity
class Person {
...
@JdbcTypeCode(SqlTypes.JSON)
Name name;
...
}We also need to add Jackson or an implementation of JSONB—for example, Yasson—to our runtime classpath. To use Jackson we could add this line to our Gradle build:
runtimeOnly 'com.fasterxml.jackson.core:jackson-databind:{jacksonVersion}'Now the name column of the Author table will have the type jsonb, and Hibernate will automatically use Jackson to serialize a Name to and from JSON format.
4.12. Summary of SQL column type mappings
So, as we’ve seen, there are quite a few annotations that affect the mapping of Java types to SQL column types in DDL. Here we summarize the ones we’ve just seen in the second half of this chapter, along with some we already mentioned in earlier chapters.
| Annotation | Interpretation |
|---|---|
@Enumerated | Specify how an enum type should be persisted |
@Nationalized | Use a nationalized character type: NCHAR, NVARCHAR, or NCLOB |
@Lob 💀 | Use JDBC LOB APIs to read and write the annotated attribute |
@Array | Map a collection to a SQL ARRAY type of the specified length |
@Struct | Map an embeddable to a SQL UDT with the given name |
@TimeZoneStorage | Specify how the time zone information should be persisted |
@JdbcType or @JdbcTypeCode | Use an implementation of JdbcType to map an arbitrary SQL type |
In addition, there are some configuration properties which have a global affect on how basic types map to SQL column types:
| Configuration property name | Purpose |
|---|---|
hibernate.use_nationalized_character_data | Enable use of nationalized character types by default |
hibernate.type.preferred_boolean_jdbc_type | Specify the default SQL column type for mapping boolean |
hibernate.type.preferred_uuid_jdbc_type | Specify the default SQL column type for mapping UUID |
hibernate.type.preferred_duration_jdbc_type | Specify the default SQL column type for mapping Duration |
hibernate.type.preferred_instant_jdbc_type | Specify the default SQL column type for mapping Instant |
hibernate.timezone.default_storage | Specify the default strategy for storing time zone information |
| 这些是全局设置,因此相当笨拙。我们建议不要弄乱这些设置,除非您有充分的理由。 | |
|---|---|
我们想在本章中讨论另一个主题。
4.13. 映射到公式
Hibernate 允许我们将实体的属性映射到涉及映射表的列的 SQL 公式。因此,属性是一种“派生”值。
| 注解 | 目的 |
|---|---|
@Formula | 将属性映射到 SQL 公式 |
@JoinFormula | 将关联映射到 SQL 公式 |
@DiscriminatorFormula | 使用 SQL 公式作为单表继承中的判别器。 |
例如:
@Entity
class Order {
...
@Column(name = "sub_total", scale=2, precision=8)
BigDecimal subTotal;
@Column(name = "tax", scale=4, precision=4)
BigDecimal taxRate;
@Formula("sub_total * (1.0 + tax)")
BigDecimal totalWithTax;
...
}4.14. 派生身份
如果一个实体从关联的“父”实体继承了其主键的一部分,则该实体具有*派生身份。*当我们讨论与共享主键的一对一关联时,我们已经遇到了派生身份的一种退化情况。
但@ManyToOne关联也可以构成派生身份的一部分。也就是说,可能存在一个或多个外键列作为复合主键的一部分。在 Java 方面可以用三种不同的方式来表示这种情况:
- 使用
@IdClass无@MapsId, @IdClass与@MapsId, 或 一起使用@EmbeddedId与 一起使用@MapsId。
假设我们有一个Parent实体类,定义如下:
@Entity
class Parent {
@Id
Long parentId;
...
}该parentId字段保存表的主键Parent,该字段也将构成Child属于Parent.
第一种方式
在第一种稍微简单的方法中,我们定义 an@IdClass来表示 的主键Child:
class DerivedId {
Long parent;
String childId;
// constructors, equals, hashcode, etc
...
}以及带有注释的关联的Child实体类:@ManyToOne``@Id
@Entity
@IdClass(DerivedId.class)
class Child {
@Id
String childId;
@Id @ManyToOne
@JoinColumn(name="parentId")
Parent parent;
...
}那么表的主键Child由列组成(childId,parentId)。
第二种方式
这很好,但有时为主键的每个元素都有一个字段会更好。我们可以使用之前@MapsId遇到的注释:
@Entity
@IdClass(DerivedId.class)
class Child {
@Id
Long parentId;
@Id
String childId;
@ManyToOne
@MapsId(Child_.PARENT_ID) // typesafe reference to Child.parentId
@JoinColumn(name="parentId")
Parent parent;
...
}我们使用之前看到的方法以类型安全的方式引用parentId的属性。Child
请注意,我们必须将列映射信息放置在被注释的关联上@MapsId,而不是@Id字段上。
我们必须稍微修改一下,@IdClass以便字段名称对齐:
class DerivedId {
Long parentId;
String childId;
// constructors, equals, hashcode, etc
...
}第三条路
第三种选择是将我们重新定义@IdClass为@Embeddable. 我们实际上不需要更改DerivedId类,但我们确实需要添加注释。
@Embeddable
class DerivedId {
Long parentId;
String childId;
// constructors, equals, hashcode, etc
...
}那么我们可以@EmbeddedId使用Child:
@Entity
class Child {
@EmbeddedId
DerivedId id;
@ManyToOne
@MapsId(DerivedId_.PARENT_ID) // typesafe reference to DerivedId.parentId
@JoinColumn(name="parentId")
Parent parent;
...
}和之间的选择归结为口味。也许有点干燥。@IdClass``@EmbeddedId``@EmbeddedId
4.15. 添加约束
数据库约束很重要。即使您确定您的程序没有错误🧐,它也可能不是唯一可以访问数据库的程序。约束有助于确保不同的程序(和人类管理员)能够很好地协作。
Hibernate 自动向生成的 DDL 添加某些约束:主键约束、外键约束和一些唯一约束。但通常需要:
- 添加额外的唯一约束,
- 添加检查约束,或者
- 自定义外键约束的名称。
我们已经了解了如何使用@ForeignKey来指定外键约束的名称。
有两种方法可以向表添加唯一约束:
- 用于
@Column(unique=true)指示单列唯一键,或 - 使用
@UniqueConstraint注释来定义列组合的唯一性约束。
@Entity
@Table(uniqueConstraints=@UniqueConstraint(columnNames={"title", "year", "publisher_id"}))
class Book { ... }这个注释看起来可能有点难看,但实际上即使作为文档也是有用的。
该@Check注释向表添加了检查约束。
@Entity
@Check(name="ValidISBN", constraints="length(isbn)=13")
class Book { ... }注解@Check通常用在字段级别:
@Id @Check(constraints="length(isbn)=13")
String isbn;5. 与数据库交互
要与数据库交互,即执行查询或插入、更新或删除数据,我们需要以下对象之一的实例:
- 一个 JPA
EntityManager, - 休眠
Session,或 - 一个休眠
StatelessSession。
该Session接口扩展了EntityManager,因此两个接口之间的唯一区别是Session提供了更多操作。
实际上,在 Hibernate 中, everyEntityManager都是 a Session,你可以这样缩小范围:Session session = entityManager.unwrap(Session.class); | |
|---|---|
Session的(或)实例EntityManager是有状态会话。它通过对持久性上下文的操作来协调程序和数据库之间的交互。
在本章中,我们不会谈论太多StatelessSession。当我们谈论性能时,我们将回到这个非常有用的 API 。您现在需要知道的是无状态会话没有持久性上下文。
不过,我们应该让您知道,有些人更喜欢在任何地方使用StatelessSession。它是一个更简单的编程模型,可以让开发人员更直接地与数据库交互。有状态会话当然有其优点,但它们更难以推理,并且当出现问题时,错误消息可能更难以理解。 | |
|---|---|
5.1. 持久化上下文
A persistence context is a sort of cache; we sometimes call it the "first-level cache", to distinguish it from the second-level cache. For every entity instance read from the database within the scope of a persistence context, and for every new entity made persistent within the scope of the persistence context, the context holds a unique mapping from the identifier of the entity instance to the instance itself.
Thus, an entity instance may be in one of three states with respect to a given persistence context:
- transient — never persistent, and not associated with the persistence context,
- persistent — currently associated with the persistence context, or
- detached — previously persistent in another session, but not currently associated with this persistence context.
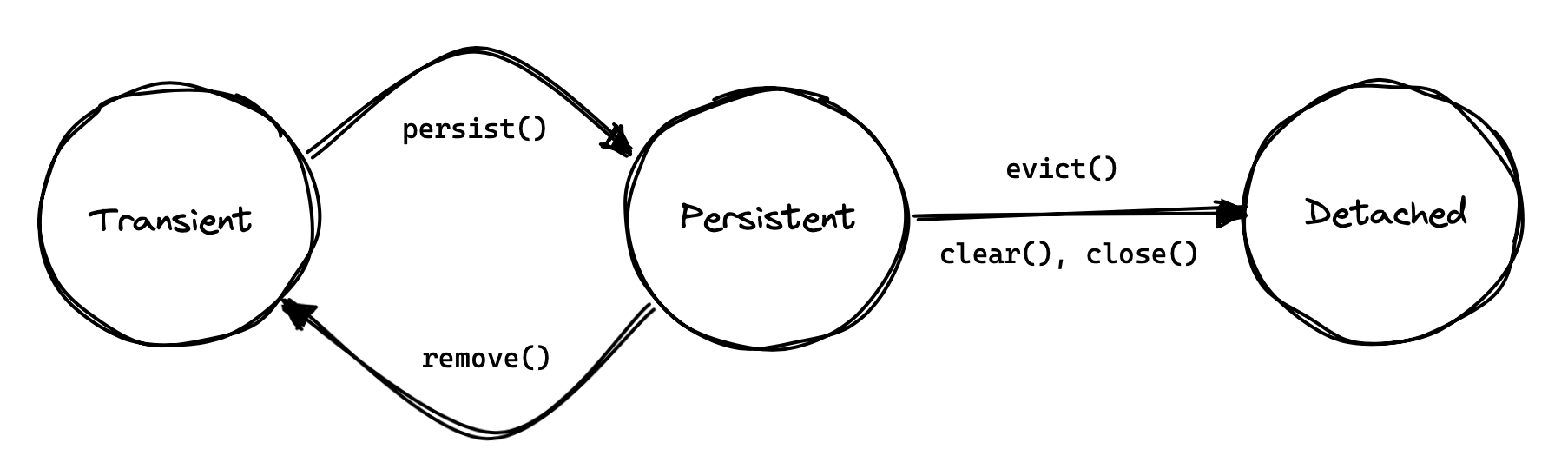
At any given moment, an instance may be associated with at most one persistence context.
The lifetime of a persistence context usually corresponds to the lifetime of a transaction, though it’s possible to have a persistence context that spans several database-level transactions that form a single logical unit of work.
A persistence context—that is, a Session or EntityManager—absolutely positively **must not be shared between multiple threads or between concurrent transactions.**If you accidentally leak a session across threads, you will suffer. | |
|---|---|
Container-managed persistence contexts
In a container environment, the lifecycle of a persistence context scoped to the transaction will usually be managed for you.
There are several reasons we like persistence contexts.
- They help avoid data aliasing: if we modify an entity in one section of code, then other code executing within the same persistence context will see our modification.
- They enable automatic dirty checking: after modifying an entity, we don’t need to perform any explicit operation to ask Hibernate to propagate that change back to the database. Instead, the change will be automatically synchronized with the database when the session is flushed.
- They can improve performance by avoiding a trip to the database when a given entity instance is requested repeatedly in a given unit of work.
- They make it possible to transparently batch together multiple database operations.
A persistence context also allows us to detect circularities when performing operations on graphs of entities. (Even in a stateless session, we need some sort of temporary cache of the entity instances we’ve visited while executing a query.)
On the other hand, stateful sessions come with some very important restrictions, since:
- persistence contexts aren’t threadsafe, and can’t be shared across threads, and
- a persistence context can’t be reused across unrelated transactions, since that would break the isolation and atomicity of the transactions.
Furthermore, a persistence context holds a hard references to all its entities, preventing them from being garbage collected. Thus, the session must be discarded once a unit of work is complete.
If you don’t completely understand the previous passage, go back and re-read it until you do. A great deal of human suffering has resulted from users mismanaging the lifecycle of the Hibernate Session or JPA EntityManager. | |
|---|---|
We’ll conclude by noting that whether a persistence context helps or harms the performance of a given unit of work depends greatly on the nature of the unit of work. For this reason Hibernate provides both stateful and stateless sessions.
5.2. Creating a session
Sticking with standard JPA-defined APIs, we saw how to obtain an EntityManagerFactory in Configuration using JPA XML. It’s quite unsurprising that we may use this object to create an EntityManager:
EntityManager entityManager = entityManagerFactory.createEntityManager();When we’re finished with the EntityManager, we should explicitly clean it up:
entityManager.close();On the other hand, if we’re starting from a SessionFactory, as described in Configuration using Hibernate API, we may use:
Session session = sessionFactory.openSession();But we still need to clean up:
session.close();Injecting the EntityManager
If you’re writing code for some sort of container environment, you’ll probably obtain the EntityManager by some sort of dependency injection. For example, in Java (or Jakarta) EE you would write:
@PersistenceContext EntityManager entityManager;In Quarkus, injection is handled by CDI:
@Inject EntityManager entityManager;Outside a container environment, we’ll also have to write code to manage database transactions.
5.3. Managing transactions
Using JPA-standard APIs, the EntityTransaction interface allows us to control database transactions. The idiom we recommend is the following:
EntityManager entityManager = entityManagerFactory.createEntityManager();
EntityTransaction tx = entityManager.getTransaction();
try {
tx.begin();
//do some work
...
tx.commit();
}
catch (Exception e) {
if (tx.isActive()) tx.rollback();
throw e;
}
finally {
entityManager.close();
}Using Hibernate’s native APIs we might write something really similar, but since this sort of code is extremely tedious, we have a much nicer option:
sessionFactory.inTransaction(session -> {
//do the work
...
});Container-managed transactions
In a container environment, the container itself is usually responsible for managing transactions. In Java EE or Quarkus, you’ll probably indicate the boundaries of the transaction using the @Transactional annotation.
5.4. Operations on the persistence context
Of course, the main reason we need an EntityManager is to do stuff to the database. The following important operations let us interact with the persistence context and schedule modifications to the data:
| Method name and parameters | Effect |
|---|---|
persist(Object) | Make a transient object persistent and schedule a SQL insert statement for later execution |
remove(Object) | Make a persistent object transient and schedule a SQL delete statement for later execution |
merge(Object) | Copy the state of a given detached object to a corresponding managed persistent instance and return the persistent object |
detach(Object) | Disassociate a persistent object from a session without affecting the database |
clear() | Empty the persistence context and detach all its entities |
flush() | Detect changes made to persistent objects association with the session and synchronize the database state with the state of the session by executing SQL insert, update, and delete statements |
Notice that persist() and remove() have no immediate effect on the database, and instead simply schedule a command for later execution. Also notice that there’s no update() operation for a stateful session. Modifications are automatically detected when the session is flushed.
On the other hand, except for getReference(), the following operations all result in immediate access to the database:
| Method name and parameters | Effect |
|---|---|
find(Class,Object) | Obtain a persistent object given its type and its id |
find(Class,Object,LockModeType) | Obtain a persistent object given its type and its id, requesting the given optimistic or pessimistic lock mode |
getReference(Class,id) | Obtain a reference to a persistent object given its type and its id, without actually loading its state from the database |
getReference(Object) | Obtain a reference to a persistent object with the same identity as the given detached instance, without actually loading its state from the database |
refresh(Object) | Refresh the persistent state of an object using a new SQL select to retrieve its current state from the database |
refresh(Object,LockModeType) | Refresh the persistent state of an object using a new SQL select to retrieve its current state from the database, requesting the given optimistic or pessimistic lock mode |
lock(Object, LockModeType) | Obtain an optimistic or pessimistic lock on a persistent object |
Any of these operations might throw an exception. Now, if an exception occurs while interacting with the database, there’s no good way to resynchronize the state of the current persistence context with the state held in database tables.
Therefore, a session is considered to be unusable after any of its methods throws an exception.
| The persistence context is fragile. If you receive an exception from Hibernate, you should immediately close and discard the current session. Open a new session if you need to, but throw the bad one away first. | |
|---|---|
Each of the operations we’ve seen so far affects a single entity instance passed as an argument. But there’s a way to set things up so that an operation will propagate to associated entities.
5.5. Cascading persistence operations
It’s quite often the case that the lifecycle of a child entity is completely dependent on the lifecycle of some parent. This is especially common for many-to-one and one-to-one associations, though it’s very rare for many-to-many associations.
For example, it’s quite common to make an Order and all its Items persistent in the same transaction, or to delete a Project and its Filess at once. This sort of relationship is sometimes called a whole/part-type relationship.
Cascading is a convenience which allows us to propagate one of the operations listed in Operations on the persistence context from a parent to its children. To set up cascading, we specify the cascade member of one of the association mapping annotations, usually @OneToMany or @OneToOne.
@Entity
class Order {
...
@OneToMany(mappedby=Item_.ORDER,
// cascade persist(), remove(), and refresh() from Order to Item
cascade={PERSIST,REMOVE,REFRESH},
// also remove() orphaned Items
orphanRemoval=true)
private Set<Item> items;
...
}Orphan removal indicates that an Item should be automatically deleted if it is removed from the set of items belonging to its parent Order.
5.6. Proxies and lazy fetching
Our data model is a set of interconnected entities, and in Java our whole dataset would be represented as an enormous interconnected graph of objects. It’s possible that this graph is disconnected, but more likely it’s connected, or composed of a relatively small number of connected subgraphs.
Therefore, when we retrieve on object belonging to this graph from the database and instantiate it in memory, we simply can’t recursively retrieve and instantiate all its associated entities. Quite aside from the waste of memory on the VM side, this process would involve a huge number of round trips to the database server, or a massive multidimensional cartesian product of tables, or both. Instead, we’re forced to cut the graph somewhere.
Hibernate solves this problem using proxies and lazy fetching. A proxy is an object that masquerades as a real entity or collection, but doesn’t actually hold any state, because that state has not yet been fetched from the database. When you call a method of the proxy, Hibernate will detect the call and fetch the state from the database before allowing the invocation to proceed to the real entity object or collection.
Now for the gotchas:
- Hibernate will only do this for an entity which is currently associated with a persistence context. Once the session ends, and the persistence context is cleaned up, the proxy is no longer fetchable, and instead its methods throw the hated
LazyInitializationException. - A round trip to the database to fetch the state of a single entity instance is just about the least efficient way to access data. It almost inevitably leads to the infamous N+1 selects problem we’ll discuss later when we talk about how to optimize association fetching.
We’re getting a bit ahead of ourselves here, but let’s quickly mention the general strategy we recommend to navigate past these gotchas:所有关联都应设置fetch=LAZY为避免在不需要时获取额外数据。正如我们之前提到的,此设置不是关联的默认设置@ManyToOne,必须明确指定。但要努力避免编写触发延迟获取的代码。相反,使用关联获取中描述的技术之一,通常在 HQL 或.EntityGraph | |
|---|---|
重要的是要知道,可以使用未获取的代理执行的某些操作不需要从数据库中获取其状态。首先,我们总是可以获取它的标识符:
var pubId = entityManager.find(Book.class, bookId).getPublisher().getId(); // does not fetch publisher其次,我们可以创建与代理的关联:
book.setPublisher(entityManager.getReference(Publisher.class, pubId)); // does not fetch publisher有时,测试是否已从数据库中获取代理或集合很有用。JPA 让我们可以使用以下方法来做到这一点PersistenceUnitUtil:
boolean authorsFetched = entityManagerFactory.getPersistenceUnitUtil().isLoaded(book.getAuthors());Hibernate 有一个稍微简单一点的方法:
boolean authorsFetched = Hibernate.isInitialized(book.getAuthors());但是类的静态方法Hibernate让我们可以做更多的事情,并且值得稍微熟悉一下它们。
特别令人感兴趣的是允许我们处理未获取的集合而无需从数据库获取其状态的操作。例如,考虑以下代码:
Book book = session.find(Book.class, bookId); // fetch just the Book, leaving authors unfetched
Author authorRef = session.getReference(Author.class, authorId); // obtain an unfetched proxy
boolean isByAuthor = Hibernate.contains(book.getAuthors(), authorRef); // no fetching此代码片段使集合book.authors和代理authorRef均未获取。
最后,Hibernate.initialize()是一个强制获取代理或集合的便捷方法:
Book book = session.find(Book.class, bookId); // fetch just the Book, leaving authors unfetched
Hibernate.initialize(book.getAuthors()); // fetch the Authors但当然,这段代码效率非常低,需要两次访问数据库才能获取原则上只需一次查询即可检索的数据。
从上面的讨论可以清楚地看出,我们需要一种方法来请求使用数据库急切地join获取关联,从而保护我们免受臭名昭著的 N+1 选择的影响。一种方法是传递EntityGraphto find()。
5.7. 实体图和急切获取
当关联被映射时fetch=LAZY,默认情况下,当我们调用该方法时,它不会被获取find()。EntityGraph我们可以通过传递to来请求急切(立即)获取关联find()。
JPA 标准 API 对此有点笨拙:
var graph = entityManager.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
Book book = entityManager.find(Book.class, bookId, Map.of(SpecHints.HINT_SPEC_FETCH_GRAPH, graph));这是不类型安全的并且不必要的冗长。Hibernate有更好的方法:
var graph = session.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
Book book = session.byId(Book.class).withFetchGraph(graph).load(bookId);此代码将 a 添加left outer join到我们的 SQL 查询中,获取关联Publisher的Book.
我们甚至可以将额外的节点附加到我们的EntityGraph:
var graph = session.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
graph.addPluralSubgraph(Book_.authors).addSubgraph(Author_.person);
Book book = session.byId(Book.class).withFetchGraph(graph).load(bookId);这会导致 SQL 查询包含四个 left outer joins。
在上面的代码示例中,类Book_和Author_是由我们之前看到的JPA 元模型生成器生成的。它们让我们以完全类型安全的方式引用模型的属性。下面,当我们讨论条件查询时,我们将再次使用它们。 | |
|---|---|
JPA 指定任何给定的内容都EntityGraph可以用两种不同的方式解释。
- 获取图准确地指定了应该急切加载的关联。仅在需要时才代理和延迟加载任何不属于实体图的关联。
- 加载图指定除了映射的关联之外还要获取实体图中的关联
fetch=EAGER。
你是对的,这些名字毫无意义。但不用担心,如果您接受我们的建议并映射您的关联fetch=LAZY,“获取”图和“加载”图之间没有区别,因此名称并不重要。
| JPA 甚至指定了一种使用注释定义命名实体图的方法。但基于注释的 API 过于冗长,不值得使用。 | |
|---|---|
5.8. 刷新会话
有时会触发刷新操作,会话会将内存中保存的脏状态(即对与持久性上下文关联的实体的状态的修改)与数据库中保存的持久状态进行同步。当然,它是通过执行 SQL INSERT、UPDATE、 和DELETE语句来做到这一点的。
默认情况下,会触发刷新:
- 当前事务提交时,例如
Transaction.commit()调用时, - 在执行查询之前,其结果将受到内存中保存的脏状态同步的影响,或者
- 当程序直接调用
flush().
请注意,SQL 语句通常不会通过和Session等接口的方法同步执行。如果需要同步执行 SQL,则允许这样做。persist()``remove()``StatelessSession | |
|---|---|
可以通过显式设置刷新模式来控制此行为。例如,要禁用查询执行之前发生的刷新,请调用:
entityManager.setFlushMode(FlushModeType.COMMIT);Hibernate 比 JPA 允许更好地控制刷新模式:
session.setHibernateFlushMode(FlushMode.MANUAL);由于刷新是一个有点昂贵的操作(会话必须对持久性上下文中的每个实体进行脏检查),因此将刷新模式设置为COMMIT有时可能是一种有用的优化。
休眠FlushMode | 日本PAFlushModeType | 解释 |
|---|---|---|
MANUAL | 切勿自动冲水 | |
COMMIT | COMMIT | 事务提交前刷新 |
AUTO | AUTO | 在事务提交之前以及执行其结果可能受到内存中保存的修改影响的查询之前刷新 |
ALWAYS | 在事务提交之前以及执行每个查询之前刷新 |
降低刷新成本的第二种方法是以只读模式加载实体:
Session.setDefaultReadOnly(false)指定默认情况下应以只读模式加载给定会话加载的所有实体,SelectionQuery.setReadOnly(false)指定给定查询返回的每个实体应以只读模式加载,并且Session.setReadOnly(Object, false)指定会话已加载的给定实体应切换到只读模式。
没有必要在只读模式下对实体实例进行脏检查。
5.9. 查询
Hibernate 具有三种互补的查询编写方式:
- Hibernate查询语言,JPQL 的极其强大的超集,它抽象了 SQL 现代方言的大部分功能,
- JPA标准查询API 以及扩展,允许通过类型安全 API 以编程方式构建几乎所有 HQL 查询,当然
- 当所有其他方法都失败时,使用本机 SQL查询。
5.10. HQL查询
对查询语言的全面讨论几乎需要与本简介的其余部分一样多的文本。幸运的是, 《Hibernate 查询语言指南》中已经对 HQL 进行了详尽(且详尽)的描述。在这里重复这些信息是没有意义的。
Session这里我们想看看如何通过or API执行查询EntityManager。我们调用的方法取决于它是什么类型的查询:
- 选择查询返回结果列表,但不修改数据,而是
- 突变查询修改数据,并返回修改的行数。
选择查询通常以关键字selector开头from,而突变查询通常以关键字insert, update, ordelete开头。
| 种类 | Session方法 | EntityManager方法 | Query执行方法 |
|---|---|---|---|
| 选择 | createSelectionQuery(String,Class) | createQuery(String,Class) | getResultList(), getSingleResult(), 或getSingleResultOrNull() |
| 突变 | createMutationQuery(String) | createQuery(String) | executeUpdate() |
所以对于SessionAPI 我们会这样写:
List<Book> matchingBooks =
session.createSelectionQuery("from Book where title like :titleSearchPattern", Book.class)
.setParameter("titleSearchPattern", titleSearchPattern)
.getResultList();或者,如果我们坚持使用 JPA 标准 API:
List<Book> matchingBooks =
entityManager.createQuery("select b from Book b where b.title like :titleSearchPattern", Book.class)
.setParameter("titleSearchPattern", titleSearchPattern)
.getResultList();
createSelectionQuery()`和之间的唯一区别`createQuery()`是,如果传递、或 ,`createSelectionQuery()`则会引发异常。`insert``delete``update在上面的查询中,:titleSearchPattern称为命名参数。我们还可以通过数字来识别参数。这些称为序数参数。
List<Book> matchingBooks =
session.createSelectionQuery("from Book where title like ?1", Book.class)
.setParameter(1, titleSearchPattern)
.getResultList();当查询有多个参数时,命名参数往往更容易阅读,即使稍微冗长一些。
切勿将用户输入与 HQL 连接并将连接的字符串传递给createSelectionQuery(). 这将为攻击者在您的数据库服务器上执行任意代码提供可能性。 | |
|---|---|
如果我们期望查询返回单个结果,我们可以使用getSingleResult().
Book book =
session.createSelectionQuery("from Book where isbn = ?1", Book.class)
.setParameter(1, isbn)
.getSingleResult();或者,如果我们期望它最多返回一个结果,我们可以使用getSingleResultOrNull().
Book bookOrNull =
session.createSelectionQuery("from Book where isbn = ?1", Book.class)
.setParameter(1, isbn)
.getSingleResultOrNull();当然,不同之处在于,getSingleResult()如果数据库中没有匹配的行,则会抛出异常,而getSingleResultOrNull()仅返回null.
默认情况下,Hibernate 在执行查询之前会脏检查持久化上下文中的实体,以确定是否应该刷新会话。如果有许多实体与持久性上下文关联,那么这可能是一项昂贵的操作。
要禁用此行为,请将刷新模式设置为COMMIT或MANUAL:
Book bookOrNull =
session.createSelectionQuery("from Book where isbn = ?1", Book.class)
.setParameter(1, isbn)
.setHibernateFlushMode(MANUAL)
.getSingleResult();将刷新模式设置为COMMIT或MANUAL可能会导致查询返回过时的结果。 | |
|---|---|
有时,我们需要在运行时根据一组可选条件构建查询。为此,JPA 提供了一个 API,允许以编程方式构建查询。
5.11. 标准查询
想象一下,我们正在实现某种搜索屏幕,系统的用户可以通过多种不同的方式来约束查询结果集。例如,我们可以让他们按书名和/或作者姓名搜索书籍。当然,我们可以通过字符串连接来构造 HQL 查询,但这有点脆弱,所以有一个替代方案是非常好的。
HQL是根据条件对象来实现的
实际上,在 Hibernate 6 中,每个 HQL 查询在转换为 SQL 之前都会编译为条件查询。这确保了 HQL 和条件查询的语义是相同的。
首先,我们需要一个用于构建条件查询的对象。使用 JPA 标准 API,这将是一个CriteriaBuilder,我们可以从 中获取它EntityManagerFactory:
CriteriaBuilder builder = entityManagerFactory.getCriteriaBuilder();但如果我们有 a SessionFactory,我们会得到更好的东西, a HibernateCriteriaBuilder:
HibernateCriteriaBuilder builder = sessionFactory.getCriteriaBuilder();它HibernateCriteriaBuilder扩展CriteriaBuilder并添加了许多 JPQL 没有的操作。
如果您正在使用EntityManagerFactory,请不要绝望,您有两种非常好的方法来获取HibernateCriteriaBuilder与该工厂相关的信息。任何一个:HibernateCriteriaBuilder builder = entityManagerFactory.unwrap(SessionFactory.class).getCriteriaBuilder();或者简单地:HibernateCriteriaBuilder builder = (HibernateCriteriaBuilder) entityManagerFactory.getCriteriaBuilder(); | |
|---|---|
我们已准备好创建条件查询。
CriteriaQuery<Book> query = builder.createQuery(Book.class);
Root<Book> book = query.from(Book.class);
Predicate where = builder.conjunction();
if (titlePattern != null) {
where = builder.and(where, builder.like(book.get(Book_.title), titlePattern));
}
if (namePattern != null) {
Join<Book,Author> author = book.join(Book_.author);
where = builder.and(where, builder.like(author.get(Author_.name), namePattern));
}
query.select(book).where(where)
.orderBy(builder.asc(book.get(Book_.title)));这里,和以前一样,类Book_和Author_是由 Hibernate 的JPA Metamodel Generator生成的。
请注意,我们没有费心将titlePattern和namePattern作为参数。这是安全的,因为默认情况下,Hibernate 自动且透明地将传递给 的字符串视为CriteriaBuilderJDBC 参数。 | |
|---|---|
标准查询的执行几乎与 HQL 的执行完全相同。
| 种类 | Session方法 | EntityManager方法 | Query执行方法 |
|---|---|---|---|
| 选择 | createSelectionQuery(CriteriaQuery) | createQuery(CriteriaQuery) | getResultList(), getSingleResult(), 或getSingleResultOrNull() |
| 突变 | createMutationQuery(CriteriaUpdate)或者createQuery(CriteriaDelete) | createQuery(CriteriaUpdate)或者createQuery(CriteriaDelte) | executeUpdate() |
例如:
List<Book> matchingBooks =
session.createSelectionQuery(query)
.getResultList();更新、插入和删除查询的工作方式类似:
CriteriaDelete<Book> delete = builder.createCriteriaDelete(Book.class);
Root<Book> book = delete.from(Book.class);
delete.where(builder.lt(builder.year(book.get(Book_.publicationDate)), 2000));
session.createMutationQuery(delete).executeUpdate();甚至可以将 HQL 查询字符串转换为条件查询,并在执行之前以编程方式修改查询:HibernateCriteriaBuilder builder = sessionFactory.getCriteriaBuilder(); var query = builder.createQuery("from Book where year(publicationDate) > 2000", Book.class); var root = (Root<Book>) query.getRootList().get(0); query.where(builder.like(root.get(Book_.title), builder.literal("Hibernate%"))); query.orderBy(builder.asc(root.get(Book_.title)), builder.desc(root.get(Book_.isbn))); List<Book> matchingBooks = session.createSelectionQuery(query).getResultList(); | |
|---|---|
您是否发现上面的一些代码有点过于冗长?我们的确是。
5.12. 编写条件查询的更舒适的方式
实际上,JPA 标准 API 不太符合人体工程学的原因是需要调用实例CriteriaBuilder方法的所有操作,而不是将它们作为static函数。它以这种方式工作的原因是每个 JPA 提供者都有自己的CriteriaBuilder.
Hibernate 6.3 引入了帮助器类CriteriaDefinition来减少标准查询的冗长性。我们的示例如下所示:
CriteriaQuery<Book> query =
new CriteriaDefinition(entityManagerFactory, Book.class) {{
select(book);
if (titlePattern != null) {
restrict(like(book.get(Book_.title), titlePattern));
}
if (namePattern != null) {
var author = book.join(Book_.author);
restrict(like(author.get(Author_.name), namePattern));
}
orderBy(asc(book.get(Book_.title)));
}};当所有其他方法都失败时,有时甚至在此之前,我们只能选择用 SQL 编写查询。
5.13. 原生 SQL 查询
HQL 是一种功能强大的语言,有助于减少 SQL 的冗长性,并显着提高数据库之间查询的可移植性。但归根结底,ORM 的真正价值不在于避免 SQL,而在于减轻我们将 SQL 结果集返回到 Java 程序后处理它们所涉及的痛苦。正如我们前面所说,Hibernate 生成的 SQL 旨在与手写 SQL 结合使用,而本机 SQL 查询是我们提供的使这变得简单的工具之一。
| 种类 | Session方法 | EntityManager方法 | Query执行方法 |
|---|---|---|---|
| 选择 | createNativeQuery(String,Class) | createNativeQuery(String,Class) | getResultList(), getSingleResult(), 或getSingleResultOrNull() |
| 突变 | createNativeMutationQuery(String) | createNativeQuery(String) | executeUpdate() |
| 存储过程 | createStoredProcedureCall(String) | createStoredProcedureQuery(String) | execute() |
对于最简单的情况,Hibernate 可以推断结果集的形状:
Book book =
session.createNativeQuery("select * from Books where isbn = ?1", Book.class)
.getSingleResult();
String title =
session.createNativeQuery("select title from Books where isbn = ?1", String.class)
.getSingleResult();但是,一般来说,JDBC 中没有足够的信息ResultSetMetaData来推断列到实体对象的映射。因此,对于更复杂的情况,您需要使用@SqlResultSetMapping注释来定义命名映射,并将名称传递给createNativeQuery(). 这会变得相当混乱,所以我们不想通过向您展示一个示例来伤害您的眼睛。
默认情况下,Hibernate 在执行本机查询之前不会刷新会话。这是因为会话不知道内存中保存的哪些修改会影响查询的结果。
因此,如果 s 有任何未刷新的更改Book,此查询可能会返回过时的数据:
List<Book> books =
session.createNativeQuery("select * from Books")
.getResultList()有两种方法可以确保在执行此查询之前刷新持久性上下文。
flush()或者,我们可以简单地通过调用或将刷新模式设置为来强制刷新ALWAYS:
List<Book> books =
session.createNativeQuery("select * from Books")
.setHibernateFlushMode(ALWAYS)
.getResultList()或者,我们可以告诉 Hibernate 哪个修改状态会影响查询结果:
List<Book> books =
session.createNativeQuery("select * from Books")
.addSynchronizedEntityClass(Book.class)
.getResultList()您可以使用createStoredProcedureQuery()或调用存储过程createStoredProcedureCall()。 | |
|---|---|
5.14. 限制、分页和排序
如果查询可能返回的结果多于我们一次可以处理的结果,我们可以指定:
- 返回的最大行数的限制,并且,
- 可选的,一个offset,即要返回的有序结果集的第一行。
| 偏移量用于对查询结果进行分页。 | |
|---|---|
有两种方法可以向 HQL 或本机 SQL 查询添加限制或偏移量:
- 使用查询语言本身的语法,例如 ,
offset 10 rows fetch next 20 rows only或 - 使用接口的方法
setFirstResult()和方法。setMaxResults()``SelectionQuery
如果限制或偏移被参数化,则第二个选项更简单。例如,这个:
List<Book> books =
session.createSelectionQuery("from Book where title like ?1 order by title")
.setParameter(1, titlePattern)
.setMaxResults(MAX_RESULTS)
.getResultList();比以下更简单:
List<Book> books =
session.createSelectionQuery("from Book where title like ?1 order by title fetch first ?2 rows only")
.setParameter(1, titlePattern)
.setParameter(2, MAX_RESULTS)
.getResultList();HibernateSelectionQuery对查询结果进行分页的方式略有不同:
List<Book> books =
session.createSelectionQuery("from Book where title like ?1 order by title")
.setParameter(1, titlePattern)
.setPage(Page.first(MAX_RESULTS))
.getResultList();一个密切相关的问题是排序。分页与按运行时确定的字段对查询结果进行排序的需要相结合是很常见的。因此,作为 HQLorder by子句的一种替代方案,SelectionQuery它提供了指定查询结果应按查询返回的实体类型的一个或多个字段进行排序的功能:
List<Book> books =
session.createSelectionQuery("from Book where title like ?1")
.setParameter(1, titlePattern)
.setOrder(List.of(Order.asc(Book._title), Order.asc(Book._isbn)))
.setMaxResults(MAX_RESULTS)
.getResultList();不幸的是,没有办法使用 JPA 的TypedQuery接口来做到这一点。
| 方法名称 | 目的 | JPA标准 |
|---|---|---|
setMaxResults() | 设置查询返回结果数的限制 | ✔ |
setFirstResult() | 设置查询返回结果的偏移量 | ✔ |
setPage() | Page通过指定对象设置限制和偏移 | ✖ |
setOrder() | 指定查询结果的排序方式 | ✖ |
5.15. 表示投影列表
投影列表是查询返回的内容的列表,即子句中的表达式列表select。由于 Java 没有元组类型,因此在 Java 中表示查询投影列表一直是 JPA 和 Hibernate 的一个问题。传统上,我们Object[]大部分时间只是使用:
var results =
session.createSelectionQuery("select isbn, title from Book", Object[].class)
.getResultList();
for (var result : results) {
var isbn = (String) result[0];
var title = (String) result[1];
...
}这实在是有点难看。Java 的record类型现在提供了一个有趣的替代方案:
record IsbnTitle(String isbn, String title) {}
var results =
session.createSelectionQuery("select isbn, title from Book", IsbnTitle.class)
.getResultList();
for (var result : results) {
var isbn = result.isbn();
var title = result.title();
...
}请注意,我们可以record在执行查询的行之前声明。
现在,这只是表面上更安全,因为查询本身不是静态检查的,所以我们不能说它客观上更好。但也许你会发现它更美观。如果我们要在系统中传递查询结果,那么使用类型record会更好。
标准查询 API 为该问题提供了更令人满意的解决方案。考虑以下代码:
var builder = sessionFactory.getCriteriaBuilder();
var query = builder.createTupleQuery();
var book = query.from(Book.class);
var bookTitle = book.get(Book_.title);
var bookIsbn = book.get(Book_.isbn);
var bookPrice = book.get(Book_.price);
query.select(builder.tuple(bookTitle, bookIsbn, bookPrice));
var resultList = session.createSelectionQuery(query).getResultList();
for (var result: resultList) {
String title = result.get(bookTitle);
String isbn = result.get(bookIsbn);
BigDecimal price = result.get(bookPrice);
...
}这段代码显然是完全类型安全的,并且比我们希望使用 HQL 做的要好得多。
5.16. 命名查询
该@NamedQuery注释让我们定义一个 HQL 查询,该查询作为引导过程的一部分进行编译和检查。这意味着我们可以更早地发现查询中的错误,而不是等到查询实际执行。我们可以将@NamedQuery注释放在任何类上,甚至可以放在实体类上。
@NamedQuery(name="10BooksByTitle",
query="from Book where title like :titlePattern order by title fetch first 10 rows only")
class BookQueries {}我们必须确保带有@NamedQuery注释的类将被 Hibernate 扫描,或者:
- 通过添加
<class>org.hibernate.example.BookQueries</class>到persistence.xml, 或 - 通过调用
configuration.addClass(BookQueries.class).
不幸的是,JPA 的@NamedQuery注释不能放在包描述符上。因此,Hibernate提供了一个非常类似的注解,@org.hibernate.annotations.NamedQuery可以在包级别指定*。*如果我们在包级别声明命名查询,则必须调用:configuration.addPackage("org.hibernate.example")这样 Hibernate 就知道在哪里可以找到它。 | |
|---|---|
该@NamedNativeQuery注释允许我们对本机 SQL 查询执行相同的操作。使用 的优势要小得多@NamedNativeQuery,因为 Hibernate 几乎无法验证以数据库的本机 SQL 方言编写的查询的正确性。
| 种类 | Session方法 | EntityManager方法 | Query执行方法 |
|---|---|---|---|
| 选择 | createNamedSelectionQuery(String,Class) | createNamedQuery(String,Class) | getResultList(), getSingleResult(), 或getSingleResultOrNull() |
| 突变 | createNamedMutationQuery(String) | createNamedQuery(String) | executeUpdate() |
我们像这样执行命名查询:
List<Book> books =
entityManager.createNamedQuery(BookQueries_.QUERY_10_BOOKS_BY_TITLE)
.setParameter("titlePattern", titlePattern)
.getResultList()这里,BookQueries_.QUERY_10_BOOKS_BY_TITLE是一个值为 的常量"10BooksByTitle",由元模型生成器生成。
请注意,执行命名查询的代码不知道查询是用 HQL 还是本机 SQL 编写的,这使得以后更改和优化查询变得稍微容易一些。
很高兴在启动时检查我们的查询。最好在编译时检查它们。在组织持久性逻辑中,我们提到元模型生成器可以在注释的帮助下为我们做到这一点,@CheckHQL并且我们将其作为使用的理由@NamedQuery。但实际上,Hibernate 有一个单独的查询验证器,能够对作为createQuery()和 朋友参数出现的 HQL 查询字符串执行编译时验证。如果我们使用查询验证器,那么使用命名查询并没有太大的优势。 | |
|---|---|
5.17. 通过 id 控制查找
我们可以通过 HQL、条件或本机 SQL 查询执行几乎任何操作。但是,当我们已经知道所需实体的标识符时,查询可能会让人感觉有点矫枉过正。并且查询并没有有效利用二级缓存。
我们find()之前就见过这个方法。这是通过 id 执行查找的最基本方法。但正如我们已经看到的,它并不能完成所有事情。因此,Hibernate 有一些 API 可以简化某些更复杂的查找:
| 方法名称 | 目的 |
|---|---|
byId() | EntityGraph正如我们所见,让我们通过 an 指定关联获取;还允许我们指定一些附加选项,包括查找如何与二级缓存交互,以及实体是否应该以只读模式加载 |
byMultipleIds() | 让我们同时加载一批id |
当我们需要通过id检索同一实体类的多个实例时,批量加载非常有用:
var graph = session.createEntityGraph(Book.class);
graph.addSubgraph(Book_.publisher);
List<Book> books =
session.byMultipleIds(Book.class)
.withFetchGraph(graph) // control association fetching
.withBatchSize(20) // specify an explicit batch size
.with(CacheMode.GET) // control interaction with the cache
.multiLoad(bookIds);给定的列表bookIds将分为多个批次,每个批次都将从数据库中以单个select. 如果我们没有明确指定批量大小,则会自动选择批量大小。
我们还有一些通过自然 id进行查找的操作:
| 方法名称 | 目的 |
|---|---|
bySimpleNaturalId() | 对于只有一个属性的实体进行注释@NaturalId |
byNaturalId() | 对于具有多个属性的实体进行注释@NaturalId |
byMultipleNaturalId() | 让我们同时加载一批自然ID |
以下是我们如何通过复合自然 id 检索实体:
Book book =
session.byNaturalId(Book.class)
.using(Book_.isbn, isbn)
.using(Book_.printing, printing)
.load();请注意,此代码片段是完全类型安全的,这再次感谢元模型生成器。
5.18. 直接与 JDBC 交互
有时我们会遇到需要编写一些直接调用 JDBC 的代码的情况。不幸的是,JPA 没有提供很好的方法来做到这一点,但 HibernateSession可以。
session.doWork(connection -> {
try (var callable = connection.prepareCall("{call myproc(?)}")) {
callable.setLong(1, argument);
callable.execute();
}
});The Connection passed to the work is the same connection being used by the session, and so any work performed using that connection occurs in the same transaction context.
If the work returns a value, use doReturningWork() instead of doWork().
| In a container environment where transactions and database connections are managed by the container, this might not be the easiest way to obtain the JDBC connection. | |
|---|---|
5.19. What to do when things go wrong
Object/relational mapping has been called the "Vietnam of computer science". The person who made this analogy is American, and so one supposes that he meant to imply some kind of unwinnable war. This is quite ironic, since at the very moment he made this comment, Hibernate was already on the brink of winning the war.
Today, Vietnam is a peaceful country with exploding per-capita GDP, and ORM is a solved problem. That said, Hibernate is complex, and ORM still presents many pitfalls for the inexperienced, even occasionally for the experienced. Sometimes things go wrong.
In this section we’ll quickly sketch some general strategies for avoiding "quagmires".
- Understand SQL and the relational model. Know the capabilities of your RDBMS. Work closely with the DBA if you’re lucky enough to have one. Hibernate is not about "transparent persistence" for Java objects. It’s about making two excellent technologies work smoothly together.
- Log the SQL executed by Hibernate. You cannot know that your persistence logic is correct until you’ve actually inspected the SQL that’s being executed. Even when everything seems to be "working", there might be a lurking N+1 selects monster.
- Be careful when modifying bidirectional associations. In principle, you should update both ends of the association. But Hibernate doesn’t strictly enforce that, since there are some situations where such a rule would be too heavy-handed. Whatever the case, it’s up to you to maintain consistency across your model.
- Never leak a persistence context across threads or concurrent transactions. Have a strategy or framework to guarantee this never happens.
- When running queries that return large result sets, take care to consider the size of the session cache. Consider using a stateless session.
- Think carefully about the semantics of the second-level cache, and how the caching policies impact transaction isolation.
- Avoid fancy bells and whistles you don’t need. Hibernate is incredibly feature-rich, and that’s a good thing, because it serves the needs of a huge number of users, many of whom have one or two very specialized needs. But nobody has all those specialized needs. In all probability, you have none of them. Write your domain model in the simplest way that’s reasonable, using the simplest mapping strategies that make sense.
- When something isn’t behaving as you expect, simplify. Isolate the problem. Find the absolute minimum test case which reproduces the behavior, before asking for help online. Most of the time, the mere act of isolating the problem will suggest an obvious solution.
- Avoid frameworks and libraries that "wrap" JPA. If there’s any one criticism of Hibernate and ORM that sometimes does ring true, it’s that it takes you too far from direct control over JDBC. An additional layer just takes you even further.
- Avoid copy/pasting code from random bloggers or stackoverflow reply guys. Many of the suggestions you’ll find online just aren’t the simplest solution, and many aren’t correct for Hibernate 6. Instead, understand what you’re doing; study the Javadoc of the APIs you’re using; read the JPA specification; follow the advice we give in this document; go direct to the Hibernate team on Zulip. (Sure, we can be a bit cantankerous at times, but we do always want you to be successful.)
- Always consider other options. You don’t have to use Hibernate for everything.
6. Compile-time tooling
The Metamodel Generator is a standard part of JPA. We’ve actually already seen its handiwork in the code examples earlier: it’s the author of the class Book_, which contains the static metamodel of the entity class Book.
The Metamodel Generator
Hibernate’s Metamodel Generator is an annotation processor that produces what JPA calls a static metamodel. That is, it produces a typed model of the persistent classes in our program, giving us a type-safe way to refer to their attributes in Java code. In particular, it lets us specify entity graphs and criteria queries in a completely type-safe way.
这件事背后的历史很有趣。当 Java 的注释处理 API 是全新的时,Gavin King 提议将 JPA 的静态元模型包含在 JPA 2.0 中,作为在新生标准查询 API 中实现类型安全的一种方法。公平地说,早在 2010 年,这个 API 并没有取得巨大的成功。当时的工具不具备对注释处理器的强大支持。所有显式泛型类型都使用户代码变得非常冗长且难以阅读。(对实例的显式引用的需要CriteriaBuilder也导致了标准 API 的冗长。)多年来,Gavin 将此视为他最令人尴尬的失误之一。
但时间对静态元模型很友善。到 2023 年,所有 Java 编译器、构建工具和 IDE 都对注释处理提供强大的支持,并且 Java 的本地类型推断(关键字var)消除了冗长的泛型类型。JPACriteriaBuilder和EntityGraphAPI 仍然不太完美,但这些缺陷与静态类型安全或注释处理无关。不可否认,静态元模型本身是有用且优雅的。
现在,在 Hibernate 6.3 中,我们终于准备好使用元模型生成器进入新的领域。事实证明,那里有相当多的未开发潜力。
现在,您仍然不必将元模型生成器与 Hibernate 一起使用——我们刚才提到的 API 仍然接受纯字符串——但我们发现它与 Gradle 配合良好,并且与我们的 IDE 顺利集成,并且在类型安全方面具有优势是引人注目的。
| 我们已经了解了如何在之前看到的Gradle 构建中设置注释处理器。 | |
|---|---|
下面是根据 JPA 规范的要求为实体类生成的代码类型的示例:
生成的代码
@StaticMetamodel(Book.class)
public abstract class Book_ {
/**
* @see org.example.Book#isbn
**/
public static volatile SingularAttribute<Book, String> isbn;
/**
* @see org.example.Book#text
**/
public static volatile SingularAttribute<Book, String> text;
/**
* @see org.example.Book#title
**/
public static volatile SingularAttribute<Book, String> title;
/**
* @see org.example.Book#type
**/
public static volatile SingularAttribute<Book, Type> type;
/**
* @see org.example.Book#publicationDate
**/
public static volatile SingularAttribute<Book, LocalDate> publicationDate;
/**
* @see org.example.Book#publisher
**/
public static volatile SingularAttribute<Book, Publisher> publisher;
/**
* @see org.example.Book#authors
**/
public static volatile SetAttribute<Book, Author> authors;
public static final String ISBN = "isbn";
public static final String TEXT = "text";
public static final String TITLE = "title";
public static final String TYPE = "type";
public static final String PUBLICATION_DATE = "publicationDate";
public static final String PUBLISHER = "publisher";
public static final String AUTHORS = "authors";
}对于实体的每个属性,该类Book_具有:
- 一个
String值常量,例如TITLE, 和 - 类型安全引用,类似于
title类型的元模型对象Attribute。
我们已经在前面的章节中使用了元模型Book_.authors引用Book.AUTHORS。现在让我们看看元模型生成器还能为我们做什么。
元模型生成器提供对 JPA 元素的静态类型Metamodel访问。但Metamodel也可以通过“反射”方式访问EntityManagerFactory.EntityType<Book> book = entityManagerFactory.getMetamodel().entity(Book.class); SingularAttribute<Book,Long> id = book.getDeclaredId(Long.class)这对于在框架或库中编写通用代码非常有用。例如,您可以使用它来创建您自己的条件查询 API。 | |
|---|---|
自动生成查找方法和查询方法是 Hibernate 实现元模型生成器的一个新功能,也是对 JPA 规范定义的功能的扩展。在本章中,我们将探讨这些功能。
| The functionality described in the rest of this chapter depends on the use of the annotations described in Entities. The Metamodel Generator is not currently able to generate finder methods and query methods for entities declared completely in XML, and it’s not able to validate HQL which queries such entities. (On the other hand, the O/R mappings may be specified in XML, since they’re not needed by the Metamodel Generator.) | |
|---|---|
We’re going to meet three different kinds of generated method:
- a named query method has its signature and implementation generated directly from a
@NamedQueryannotation, - a query method has a signature that’s explicitly declared, and a generated implementation which executes a HQL or SQL query specified via a
@HQLor@SQLannotation, and - a finder method annotated
@Findhas a signature that’s explicitly declared, and a generated implementation inferred from the parameter list.
To whet our appetites, let’s see how this works for a @NamedQuery.
6.1. Named queries and the Metamodel Generator
The very simplest way to generate a query method is to put a @NamedQuery annotation anywhere we like, with a name beginning with the magical character #.
Let’s just stick it on the Book class:
@CheckHQL // validate the query at compile time
@NamedQuery(name = "#findByTitleAndType",
query = "select book from Book book where book.title like :titlen and book.type = :type")
@Entity
public class Book { ... }Now the Metamodel Generator adds the following method declaration to the metamodel class Book_.
Generated Code
/**
* Execute named query {@value #QUERY_FIND_BY_TITLE_AND_TYPE} defined by annotation of {@link Book}.
**/
public static List<Book> findByTitleAndType(@Nonnull EntityManager entityManager, String title, Type type) {
return entityManager.createNamedQuery(QUERY_FIND_BY_TITLE_AND_TYPE)
.setParameter("titlePattern", title)
.setParameter("type", type)
.getResultList();
}We can easily call this method from wherever we like, as long as we have access to an EntityManager:
List<Book> books =
Book_.findByTitleAndType(entityManager, titlePattern, Type.BOOK);Now, this is quite nice, but it’s a bit inflexible in various ways, and so this probably isn’t the best way to generate a query method.
6.2. Generated query methods
The principal problem with generating the query method straight from the @NamedQuery annotation is that it doesn’t let us explicitly specify the return type or parameter list. In the case we just saw, the Metamodel Generator does a reasonable job of inferring the query return type and parameter types, but we’re often going to need a bit more control.
The solution is to write down the signature of the query method explicitly, as an abstract method in Java. We’ll need a place to put this method, and since our Book entity isn’t an abstract class, we’ll just introduce a new interface for this purpose:
interface Queries {
@HQL("where title like :title and type = :type")
List<Book> findBooksByTitleAndType(String title, String type);
}Instead of @NamedQuery, which is a type-level annotation, we specify the HQL query using the new @HQL annotation, which we place directly on the query method. This results in the following generated code in the Queries_ class:
Generated Code
@StaticMetamodel(Queries.class)
public abstract class Queries_ {
/**
* Execute the query {@value #FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type}.
*
* @see org.example.Queries#findBooksByTitleAndType(String,Type)
**/
public static List<Book> findBooksByTitleAndType(@Nonnull EntityManager entityManager, String title, Type type) {
return entityManager.createQuery(FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type, Book.class)
.setParameter("title", title)
.setParameter("type", type)
.getResultList();
}
static final String FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type =
"where title like :title and type = :type";
}Notice that the signature differs just slightly from the one we wrote down in the Queries interface: the Metamodel Generator has prepended a parameter accepting EntityManager to the parameter list.
如果我们想显式指定这个参数的名称和类型,我们可以显式声明它:
interface Queries {
@HQL("where title like :title and type = :type")
List<Book> findBooksByTitleAndType(StatelessSession session, String title, String type);
}元模型生成器默认使用EntityManager会话类型,但也允许其他类型:
Session,StatelessSession, 或者Mutiny.Session来自 Hibernate 反应式。
所有这一切的真正价值在于现在可以在编译时完成的检查。元模型生成器验证我们的抽象方法声明的参数是否与 HQL 查询的参数匹配,例如:
- 对于命名参数
:alice,必须有一个alice以完全相同的类型命名的方法参数,或者 - 对于序数参数
?2,第二个方法参数必须具有完全相同的类型。
查询还必须在语法上合法且语义上类型良好,即查询中引用的实体、属性和函数必须实际存在并且具有兼容的类型。元模型生成器通过在编译时检查实体类的注释来确定这一点。
对于带注释的查询方法来说,指示@CheckHQLHibernate 验证命名查询的注释不是必需@HQL的。 | |
|---|---|
该@HQL注释有一个名为的友元@SQL,它允许我们指定用本机 SQL 而不是 HQL 编写的查询。在这种情况下,元模型生成器可以做的事情要少得多,以检查查询是否合法且类型正确。
我们想象您想知道某种static方法是否真的适合在这里使用。
6.3. 生成查询方法作为实例方法
我们刚刚看到的令人不喜欢的一件事是,我们无法在不影响客户端的情况下透明地用改进的手写实现替换类的生成static函数Queries_。现在,如果我们的查询仅在一个地方调用(这很常见),那么这不会是一个大问题,因此我们倾向于认为该static函数没有问题。
但是,如果从许多地方调用此函数,最好将其提升为某个类或接口的实例方法。幸运的是,这很简单。
我们需要做的就是将会话对象的抽象 getter 方法添加到我们的Queries接口中。(并从方法参数列表中删除会话。)我们可以将此方法称为任何我们喜欢的名称:
interface Queries {
EntityManager entityManager();
@HQL("where title like :title and type = :type")
List<Book> findBooksByTitleAndType(String title, String type);
}这里我们使用了EntityManager会话类型,但是其他类型也是允许的,正如我们上面看到的。
现在元模型生成器做了一些不同的事情:
生成的代码
@StaticMetamodel(Queries.class)
public class Queries_ implements Queries {
private final @Nonnull EntityManager entityManager;
public Queries_(@Nonnull EntityManager entityManager) {
this.entityManager = entityManager;
}
public @Nonnull EntityManager entityManager() {
return entityManager;
}
/**
* Execute the query {@value #FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type}.
*
* @see org.example.Queries#findBooksByTitleAndType(String,Type)
**/
@Override
public List<Book> findBooksByTitleAndType(String title, Type type) {
return entityManager.createQuery(FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type, Book.class)
.setParameter("title", title)
.setParameter("type", type)
.getResultList();
}
static final String FIND_BOOKS_BY_TITLE_AND_TYPE_String_Type =
"where title like :title and type = :type";
}生成的类Queries_现在实现了Queries接口,生成的查询方法直接实现了我们的抽象方法。
当然,调用查询方法的协议必须改变:
Queries queries = new Queries_(entityManager);
List<Book> books = queries.findByTitleAndType(titlePattern, Type.BOOK);如果我们需要将生成的查询方法替换为我们手工编写的查询方法,而不影响客户端,那么我们所需要做的就是用接口的方法替换抽象default方法Queries。例如:
interface Queries {
EntityManager entityManager();
// handwritten method replacing previous generated implementation
default List<Book> findBooksByTitleAndType(String title, String type) {
entityManager()
.createQuery("where title like :title and type = :type", Book.class)
.setParameter("title", title)
.setParameter("type", type)
.setFlushMode(COMMIT)
.setMaxResults(100)
.getResultList();
}
}如果我们想注入一个Queries对象而不是直接调用它的构造函数怎么办?
您还记得吗,我们认为这些东西实际上不需要是容器管理的对象。但如果你希望它们是这样的——如果你出于某种原因对调用构造函数过敏——那么:放置jakarta.inject在构建路径上将导致@Inject注释被添加到 的构造函数中Queries_,并且放置jakarta.enterprise.context在构建路径上将导致将@Dependent注释添加到Queries_类中。因此,生成的实现Queries将是一个功能完美的 CDI bean,无需执行额外的工作。 | |
|---|---|
该Queries界面是否开始看起来很像 DAO 风格的存储库对象?嗯,也许吧。如果您喜欢的话,您当然可以决定使用此工具来创建一个。BookRepository但与存储库不同的是,我们的Queries界面:
EntityManager不会试图向客户隐瞒,- 不会实现或扩展任何框架提供的接口或抽象类,至少不会,除非您想自己创建这样的框架,并且
- 不限于服务特定的实体类。
我们可以根据需要拥有任意数量的带有查询方法的接口。这些接口和实体类型之间不存在一对一的对应关系。这种方法非常灵活,以至于我们甚至不知道如何称呼这些“带有查询方法的接口”。
6.4. 生成的查找器方法
此时,人们通常会开始质疑是否有必要编写查询。是否可以仅从方法签名推断查询?
在一些简单的情况下确实是可能的,这就是finder 方法的目的。finder 方法是带注释的方法@Find。例如:
@Find
Book getBook(String isbn);一个 finder 方法可能有多个参数:
@Find
List<Book> getBooksByTitle(String title, Type type);finder 方法的名称是任意的并且不带有任何语义。但:
- 返回类型决定了要查询的实体类,并且
- 该方法的参数必须与实体类的字段在名称和类型上完全匹配。
考虑到我们的第一个例子,Book有一个持久字段String isbn,所以这个 finder 方法是合法的。isbn如果中没有命名的字段Book,或者它具有不同的类型,则此方法声明将在编译时被拒绝并出现有意义的错误。同样,第二个示例是合法的,因为Book具有字段String title和Type type。
| 您可能会注意到,我们对此问题的解决方案与其他人采取的方法非常不同。在 DAO 风格的存储库框架中,要求您将 finder 方法的语义编码到方法的名称中。这个想法是从 Ruby 传到 Java 的,我们认为它不属于这里。这在 Java 中是完全不自然的,而且除了计算字符之外,从几乎任何标准来看,它客观上都比仅仅在字符串中编写查询更糟糕。至少字符串文字可以容纳空格和标点符号。哦,您知道,能够重命名查找器方法而不更改其语义是非常有用的。🙄 | |
|---|---|
为此查找器方法生成的代码取决于哪种字段与方法参数匹配:
@Id场地 | 用途EntityManager.find() |
|---|---|
所有@NaturalId领域 | 用途Session.byNaturalId() |
| 其他持久字段或字段类型的混合 | 使用条件查询 |
生成的代码还取决于我们拥有哪种类型的会话,因为无状态会话和反应式会话的功能与常规有状态会话的功能略有不同。
作为EntityManager会话类型,我们获得:
/**
* Find {@link Book} by {@link Book#isbn isbn}.
*
* @see org.example.Dao#getBook(String)
**/
@Override
public Book getBook(@Nonnull String isbn) {
return entityManager.find(Book.class, isbn);
}
/**
* Find {@link Book} by {@link Book#title title} and {@link Book#type type}.
*
* @see org.example.Dao#getBooksByTitle(String,Type)
**/
@Override
public List<Book> getBooksByTitle(String title, Type type) {
var builder = entityManager.getEntityManagerFactory().getCriteriaBuilder();
var query = builder.createQuery(Book.class);
var entity = query.from(Book.class);
query.where(
title==null
? entity.get(Book_.title).isNull()
: builder.equal(entity.get(Book_.title), title),
type==null
? entity.get(Book_.type).isNull()
: builder.equal(entity.get(Book_.type), type)
);
return entityManager.createQuery(query).getResultList();
}甚至可以将查找器方法的参数与关联实体或可嵌入的属性进行匹配。自然语法是像 那样的参数声明String publisher.name,但因为这不是合法的 Java,我们可以将其写为String publisher$name,利用从未有人将其用于其他任何用途的合法 Java 标识符字符:
@Find
List<Book> getBooksByPublisherName(String publisher$name);finder 方法可以指定fetch profile,例如:
@Find(namedFetchProfiles=Book_.FETCH_WITH_AUTHORS)
Book getBookWithAuthors(String isbn);Book这让我们可以通过注释类来声明应该预取哪些关联Book。
6.5. 分页和排序
或者,查询方法可以具有额外的“神奇”参数,这些参数不会映射到查询参数:
| 参数类型 | 目的 | 示例参数 |
|---|---|---|
Page | 指定查询结果的一页 | Page.first(20) |
Order<? super E> | E如果是查询返回的实体类型,则指定要排序的实体属性 | Order.asc(Book_.title) |
List<Order? super E> (或可变参数) | E如果是查询返回的实体类型,则指定要排序的实体属性 | List.of(Order.asc(Book_.title), Order.asc(Book_.isbn)) |
Order<Object[]> | 如果查询返回投影列表,则指定排序依据的列 | Order.asc(1) |
List<Object[]> (或可变参数) | 如果查询返回投影列表,则指定排序依据的列 | List.of(Order.asc(1), Order.desc(2)) |
因此,如果我们重新定义之前的查询方法,如下所示:
interface Queries {
@HQL("from Book where title like :title and type = :type")
List<Book> findBooksByTitleAndType(String title, Page page, Order<? super Book>... order);
}然后我们可以这样称呼它:
List<Book> books =
Queries_.findBooksByTitleAndType(entityManager, titlePattern, Type.BOOK,
Page.page(RESULTS_PER_PAGE, page), Order.asc(Book_.isbn));6.6. 查询和查找方法返回类型
查询方法不需要返回List。它可能会返回一个Book.
@HQL("where isbn = :isbn")
Book findBookByIsbn(String isbn);对于带有投影列表的查询,Object[]orList<Object[]>是允许的:
@HQL("select isbn, title from Book where isbn = :isbn")
Object[] findBookAttributesByIsbn(String isbn);但是,当列表中只有一项时select,应使用该项的类型:
@HQL("select title from Book where isbn = :isbn")
String getBookTitleByIsbn(String isbn);
@HQL("select local datetime")
LocalDateTime getServerDateTime();返回选择列表的查询可能具有将结果重新打包为记录的查询方法,正如我们在表示投影列表中看到的那样。
record IsbnTitle(String isbn, String title) {}
@HQL("select isbn, title from Book")
List<IsbnTitle> listIsbnAndTitleForEachBook(Page page);查询方法甚至可能返回TypedQueryor SelectionQuery:
@HQL("where title like :title")
SelectionQuery<Book> findBooksByTitle(String title);这有时非常有用,因为它允许客户端进一步操作查询:
List<Book> books =
Queries_.findBooksByTitle(entityManager, titlePattern)
.setOrder(Order.asc(Book_.title)) // order the results
.setPage(Page.page(RESULTS_PER_PAGE, page)) // return the given page of results
.setFlushMode(FlushModeType.COMMIT) // don't flush session before query execution
.setReadOnly(true) // load the entities in read-only mode
.setCacheStoreMode(CacheStoreMode.BYPASS) // don't cache the results
.setComment("Hello world!") // add a comment to the generated SQL
.getResultList();, , or查询必须返回or insert。update``delete``int``void
@HQL("delete from Book")
int deleteAllBooks();
@HQL("update Book set discontinued = true where isbn = :isbn")
void discontinueBook(String isbn);另一方面,目前的查找方法受到更多限制。例如,查找器方法必须返回实体类型(例如 )Book或实体类型的列表(List<Book>例如 )。
正如您所期望的,对于反应式会话,所有查询方法和查找方法都必须返回Uni。 | |
|---|---|
6.7. 另一种方法
如果您只是不喜欢我们在本章中提出的想法,更喜欢直接调用 or Session,EntityManager但您仍然希望对 HQL 进行编译时验证,该怎么办?或者,如果您确实喜欢这些想法,但您正在开发一个庞大的现有代码库,其中充满了您不想更改的代码,该怎么办?
好吧,也有一个适合您的解决方案。查询验证器是一个单独的注释处理器,它不仅能够在注释中对 HQL 字符串进行类型检查,甚至当它们作为 、 或 的参数出现时createQuery()也是createSelectionQuery()如此createMutationQuery()。它甚至可以检查对 的调用setParameter(),但有一些限制。
查询验证器适用于javac、Gradle、Maven 和 Eclipse Java 编译器。
与元模型生成器(它是仅基于标准 Java API 的完全标准 Java 注释处理器)不同,查询验证器利用 和 中的内部编译器javacAPI ecj。这意味着不能保证它在每个 Java 编译器中都能工作。已知当前版本可在 JDK 11 及更高版本中运行,但首选 JDK 15 或更高版本。 | |
|---|---|
7. 调优和性能
一旦您使用 Hibernate 启动并运行程序来访问数据库,您将不可避免地发现性能令人失望或不可接受的地方。
幸运的是,只要您牢记一些简单的原则,大多数性能问题都可以通过 Hibernate 提供的工具相对容易地解决。
首先也是最重要的:您使用 Hibernate 的原因是它使事情变得更容易。如果对于某个问题,它使事情变得更加困难,请停止使用它。使用不同的工具解决此问题。
| 仅仅因为您在程序中使用 Hibernate 并不意味着您必须在任何地方使用它。 | |
|---|---|
其次:使用 Hibernate 的程序中存在两个主要的潜在性能瓶颈来源:
- 与数据库的往返次数太多,并且
- 与一级(会话)缓存相关的内存消耗。
因此,性能调优主要涉及减少对数据库的访问次数,和/或控制会话缓存的大小。
但在讨论这些更高级的主题之前,我们应该从调整连接池开始。
7.1. 调整连接池
Hibernate 内置的连接池适合测试,但不适用于生产。相反,Hibernate 支持一系列不同的连接池,包括我们最喜欢的 Agroal。
要选择和配置 Agroal,除了我们在基本配置设置中看到的设置之外,您还需要设置一些额外的配置属性。带有前缀的属性hibernate.agroal将传递给 Agroal:
# configure Agroal connection pool
hibernate.agroal.maxSize 20
hibernate.agroal.minSize 10
hibernate.agroal.acquisitionTimeout PT1s
hibernate.agroal.reapTimeout PT10s只要您设置至少一个带有前缀 的属性hibernate.agroal,AgroalConnectionProvider就会自动选择。有很多可供选择:
| 配置属性名称 | 目的 |
|---|---|
hibernate.agroal.maxSize | 池中存在的最大连接数 |
hibernate.agroal.minSize | 池中存在的最小连接数 |
hibernate.agroal.initialSize | 启动时添加到池中的连接数 |
hibernate.agroal.maxLifetime | 连接可以存活的最长时间,超过该时间后将从池中删除 |
hibernate.agroal.acquisitionTimeout | 线程可以等待连接的最长时间,超过该时间后将引发异常 |
hibernate.agroal.reapTimeout | 驱逐空闲连接的持续时间 |
hibernate.agroal.leakTimeout | 在不导致报告泄漏的情况下可以保持连接的持续时间 |
hibernate.agroal.idleValidationTimeout | 如果连接在池上空闲的时间超过此持续时间,则会执行前台验证 |
hibernate.agroal.validationTimeout | 后台验证检查之间的间隔 |
hibernate.agroal.initialSql | 创建连接时要执行的 SQL 命令 |
以下设置对于 Hibernate 支持的所有连接池都是通用的:
hibernate.connection.autocommit | 默认自动提交模式 |
|---|---|
hibernate.connection.isolation | 默认事务隔离级别 |
容器管理的数据源
在容器环境中,通常不需要通过Hibernate配置连接池。相反,您将使用容器管理的数据源,正如我们在基本配置设置中看到的那样。
7.2. 启用语句批处理
提高某些事务性能的一个简单方法(几乎不需要任何工作)是打开自动 DML 语句批处理。批处理仅在程序在单个事务中对同一个表执行多次插入、更新或删除的情况下有用。
我们需要做的就是设置一个属性:
| 配置属性名称 | 目的 | 选择 |
|---|---|---|
hibernate.jdbc.batch_size | SQL 语句批处理的最大批处理大小 | setJdbcBatchSize() |
比 DML 语句批处理更好的是使用 HQLupdate或delete查询,甚至调用存储过程的本机 SQL! | |
|---|---|
7.3. 关联获取
在 ORM 中实现高性能意味着最大限度地减少数据库的往返次数。每当您使用 Hibernate 编写数据访问代码时,这个目标都应该是您心中最重要的目标。ORM 中最基本的经验法则是:
- 在会话/事务开始时显式指定您需要的所有数据,并通过一两个查询立即获取它,
- 然后才开始导航持久实体之间的关联。
Without question, the most common cause of poorly-performing data access code in Java programs is the problem of N+1 selects. Here, a list of N rows is retrieved from the database in an initial query, and then associated instances of a related entity are fetched using N subsequent queries.
| This isn’t a bug or limitation of Hibernate; this problem even affects typical handwritten JDBC code behind DAOs. Only you, the developer, can solve this problem, because only you know ahead of time what data you’re going to need in a given unit of work. But that’s OK. Hibernate gives you all the tools you need. | |
|---|---|
In this section we’re going to discuss different ways to avoid such "chatty" interaction with the database.
Hibernate provides several strategies for efficiently fetching associations and avoiding N+1 selects:
- outer join fetching—where an association is fetched using a
left outer join, - batch fetching—where an association is fetched using a subsequent
selectwith a batch of primary keys, and - subselect fetching—where an association is fetched using a subsequent
selectwith keys re-queried in a subselect.
Of these, you should almost always use outer join fetching. But let’s consider the alternatives first.
7.4. Batch fetching and subselect fetching
Consider the following code:
List<Book> books =
session.createSelectionQuery("from Book order by isbn", Book.class)
.getResultList();
books.forEach(book -> book.getAuthors().forEach(author -> out.println(book.title + " by " + author.name)));This code is very inefficient, resulting, by default, in the execution of N+1 select statements, where n is the number of Books.
Let’s see how we can improve on that.
SQL for batch fetching
With batch fetching enabled, Hibernate might execute the following SQL on PostgreSQL:
/* initial query for Books */
select b1_0.isbn,b1_0.price,b1_0.published,b1_0.publisher_id,b1_0.title
from Book b1_0
order by b1_0.isbn
/* first batch of associated Authors */
select a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name
from Book_Author a1_0
join Author a1_1 on a1_1.id=a1_0.authors_id
where a1_0.books_isbn = any (?)
/* second batch of associated Authors */
select a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name
from Book_Author a1_0
join Author a1_1 on a1_1.id=a1_0.authors_id
where a1_0.books_isbn = any (?)The first select statement queries and retrieves Books. The second and third queries fetch the associated Authors in batches. The number of batches required depends on the configured batch size. Here, two batches were required, so two SQL statements were executed.
The SQL for batch fetching looks slightly different depending on the database. Here, on PostgreSQL, Hibernate passes a batch of primary key values as a SQL ARRAY. | |
|---|---|
SQL for subselect fetching
On the other hand, with subselect fetching, Hibernate would execute this SQL:
/* initial query for Books */
select b1_0.isbn,b1_0.price,b1_0.published,b1_0.publisher_id,b1_0.title
from Book b1_0
order by b1_0.isbn
/* fetch all associated Authors */
select a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name
from Book_Author a1_0
join Author a1_1 on a1_1.id=a1_0.authors_id
where a1_0.books_isbn in (select b1_0.isbn from Book b1_0)Notice that the first query is re-executed in a subselect in the second query. The execution of the subselect is likely to be relatively inexpensive, since the data should already be cached by the database. Clever, huh?
Enabling the use of batch or subselect fetching
Both batch fetching and subselect fetching are disabled by default, but we may enable one or the other globally using properties.
| Configuration property name | Property value | Alternatives |
|---|---|---|
hibernate.default_batch_fetch_size | 合理的批量大小>1以启用批量获取 | @BatchSize(),setFetchBatchSize() |
hibernate.use_subselect_fetch | true启用子选择获取 | @Fetch(SUBSELECT),setSubselectFetchingEnabled() |
或者,我们可以在给定会话中启用其中之一:
session.setFetchBatchSize(5);
session.setSubselectFetchingEnabled(true);我们可以通过用注释注释集合或多值关联来请求更有选择性地获取子选择@Fetch。@ManyToMany @Fetch(SUBSELECT) Set<Author> authors;请注意,@Fetch(SUBSELECT)与 具有相同的效果@Fetch(SELECT),除非执行 HQL 或条件查询之后。但在执行查询后,@Fetch(SUBSELECT)能够更有效地获取关联。稍后,我们将了解如何使用获取配置文件更有选择性地执行此操作。 | |
|---|---|
这里的所有都是它的。太容易了,对吧?
可悲的是,这并不是故事的结局。虽然批量获取可能会缓解涉及 N+1 选择的问题,但它无法解决这些问题。真正正确的解决方案是使用连接来获取关联。批量获取(或子选择获取)仅在极少数情况下才是最佳解决方案,在这种情况下,外连接获取会导致笛卡尔积和巨大的结果集。
但批量获取和子选择获取有一个重要的共同特征:它们可以延迟执行。原则上,这非常方便。当我们查询数据,然后导航对象图时,延迟获取可以节省我们提前计划的精力。事实证明,这是我们必须放弃的便利。
7.5。加入抓取
外连接获取通常是获取关联的最佳方式,也是我们大部分时间使用的方式。不幸的是,就其本质而言,连接获取根本不能偷懒。因此,要利用连接获取,我们必须提前计划。我们的一般建议是:
| 避免使用延迟获取,这通常是 N+1 选择的根源。 | |
|---|---|
现在,我们并不是说默认情况下应该映射关联以进行急切获取!这将是一个糟糕的想法,导致简单的会话操作几乎获取整个数据库。所以:
| 默认情况下,大多数关联应映射为延迟获取。 | |
|---|---|
听起来这个提示似乎与前一个提示矛盾,但事实并非如此。这意味着您必须在需要的时间和地点明确指定对关联的急切获取。
如果我们需要在某些特定事务中进行急切连接获取,我们有四种不同的方法来指定。
通过 JPAEntityGraph | 我们已经在实体图和急切获取中看到了这一点 |
|---|---|
| 指定命名的提取配置文件 | 我们稍后将在命名获取配置文件中讨论此方法 |
left join fetch在 HQL/JPQL 中使用 | 有关详细信息,请参阅Hibernate 查询语言指南 |
From.fetch()在条件查询中使用 | join fetch与HQL 中的语义相同 |
通常,查询是最方便的选项。以下是我们如何在 HQL 中请求连接获取:
List<Book> booksWithJoinFetchedAuthors =
session.createSelectionQuery("from Book join fetch authors order by isbn")
.getResultList();这是使用 criteria API 编写的相同查询:
var builder = sessionFactory.getCriteriaBuilder();
var query = builder.createQuery(Book.class);
var book = query.from(Book.class);
book.fetch(Book_.authors);
query.select(book);
query.orderBy(builder.asc(book.get(Book_.isbn)));
List<Book> booksWithJoinFetchedAuthors =
session.createSelectionQuery(query).getResultList();select无论哪种方式,都会执行一条 SQL语句:
select b1_0.isbn,a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name,b1_0.price,b1_0.published,b1_0.publisher_id,b1_0.title
from Book b1_0
join (Book_Author a1_0 join Author a1_1 on a1_1.id=a1_0.authors_id)
on b1_0.isbn=a1_0.books_isbn
order by b1_0.isbn好多了!
尽管连接抓取具有非惰性的性质,但显然比批量或子选择抓取更有效,这就是我们建议避免使用惰性抓取的来源。
有一种有趣的情况,连接获取变得低效:当我们并行获取两个多值关联时。想象一下,我们想要在某个工作单元中获取Author.books和。Author.royaltyStatements在单个查询中连接两个集合将产生表的笛卡尔积和大型 SQL 结果集。子选择提取在这里可以解决问题,它允许我们books使用连接来提取,并royaltyStatements使用单个后续select. | |
|---|---|
当然,避免多次往返数据库的另一种方法是在 Java 客户端中缓存我们需要的数据。如果我们希望在本地缓存中找到关联的数据,我们可能根本不需要连接获取。
| 但是,如果我们无法确定所有关联数据都将位于缓存中怎么办?在这种情况下,我们也许可以通过启用批量获取来降低缓存未命中的成本。 | |
|---|---|
7.6。二级缓存
减少数据库访问次数的经典方法是使用二级缓存,允许缓存在内存中的数据在会话之间共享。
从本质上讲,二级缓存往往会破坏关系数据库中事务处理的 ACID 属性。我们不使用具有两阶段提交的分布式事务来确保对缓存和数据库的更改以原子方式发生。因此,二级缓存通常是迄今为止提高系统性能的最简单方法,但代价是使并发推理变得更加困难。因此,缓存是难以隔离和重现的潜在错误来源。
因此,默认情况下,实体没有资格存储在二级缓存中。@Cache我们必须使用from 的注释显式标记将存储在二级缓存中的每个实体org.hibernate.annotations。
但这还不够。Hibernate本身并不包含二级缓存的实现,因此需要配置一个外部缓存提供程序。
| 默认情况下禁用缓存。为了最大限度地降低数据丢失的风险,我们强制您在任何实体进入缓存之前停下来思考。 | |
|---|---|
Hibernate 将二级缓存划分为多个命名区域,每个区域一个:
- 映射实体层次结构或
- 收集作用。
例如, 、 、 和 可能有单独Author的Book缓存Author.books区域Book.authors。
每个区域都可以有自己的过期、持久性和复制策略。这些策略必须在 Hibernate 外部配置。
适当的策略取决于实体代表的数据类型。例如,程序可能对“参考”数据、事务数据和用于分析的数据具有不同的缓存策略。通常,这些策略的实现是底层缓存实现的责任。
7.7. 指定缓存哪些数据
默认情况下,没有数据可以存储在二级缓存中。
可以使用注释为实体层次结构或集合角色分配区域@Cache。如果没有显式指定区域名称,则区域名称只是实体类或集合角色的名称。
@Entity
@Cache(usage=NONSTRICT_READ_WRITE, region="Publishers")
class Publisher {
...
@Cache(usage=READ_WRITE, region="PublishedBooks")
@OneToMany(mappedBy=Book_.PUBLISHER)
Set<Book> books;
...
}@CacheHibernate 自动利用注释定义的缓存来:
find()调用时通过 id 检索实体,或者- 通过 id 解析关联。
必须在实体继承层次结构的根类@Cache上指定注释。将其放置在子类实体上是错误的。 | |
|---|---|
该@Cache注释始终指定一个CacheConcurrencyStrategy,即管理并发事务对二级缓存的访问的策略。
| 并发策略 | 解释 | 解释 |
|---|---|---|
READ_ONLY | 不可变数据只读访问 | 表示缓存的对象是不可变的,并且永远不会更新。如果更新具有此缓存并发性的实体,则会引发异常。这是最简单、最安全、性能最好的缓存并发策略。它特别适合所谓的“参考”数据。 |
NONSTRICT_READ_WRITE | 并发更新的可能性极小无锁定的读/写访问 | 指示缓存的对象有时会更新,但两个事务极不可能同时尝试更新同一数据项。该策略不使用锁。当更新项目时,缓存在更新事务完成之前和之后都会失效。但如果没有锁定,就不可能完全排除在第一个事务完成过程中第二个事务在缓存中存储或检索过时数据的可能性。 |
READ_WRITE | 并发更新是可能的,但并不常见使用软锁进行读/写访问 | 表示两个并发事务尝试同时更新同一数据项的可能性不为零。该策略使用“软”锁来防止并发事务在事务完成过程中从缓存中检索或存储过时的项目。软锁只是更新事务完成时放置在缓存中的标记条目。当存在软锁时,第二个事务可能不会从缓存中读取该项目,而是简单地直接从数据库中读取该项目,就像发生了常规缓存未命中一样。类似地,当第二个事务从往返数据库的过程中返回可能不是最新版本的内容时,软锁还可以防止第二个事务将过时的项目存储到缓存中。 |
TRANSACTIONAL | 并发更新频繁交易访问 | 表示并发写入很常见,维持二级缓存和数据库之间同步的唯一方法是使用完全事务性缓存提供程序。在这种情况下,缓存和数据库必须通过JTA或XA协议进行协作,而Hibernate本身几乎不承担维护缓存完整性的责任。 |
哪些策略有意义还可能取决于底层的二级缓存实现。
JPA 有一个类似的注释,名为@Cacheable. 不幸的是,它对我们来说几乎没有用,因为:它没有提供任何方式来指定有关缓存实体的性质以及应如何管理其缓存的任何信息,并且它可能不用于注释关联,因此我们甚至不能使用它来将集合角色标记为适合存储在二级缓存中。 | |
|---|---|
7.8。通过自然id缓存
如果我们的实体有一个自然 id,我们可以通过注释该实体来启用一个额外的缓存,该缓存保存从自然 id 到主 id 的交叉引用@NaturalIdCache。默认情况下,自然id缓存存储在二级缓存的专用区域中,与缓存的实体数据分开。
@Entity
@Cache(usage=READ_WRITE, region="Book")
@NaturalIdCache(region="BookIsbn")
class Book {
...
@NaturalId
String isbn;
@NaturalId
int printing;
...
}当使用通过自然 idSession执行查找的操作之一检索实体时,将利用此缓存。
由于自然id缓存不包含实体的实际状态,因此对实体进行注释是没有意义的,@NaturalIdCache除非它已经符合在二级缓存中存储的条件,也就是说,除非它也被注释了@Cache。 | |
|---|---|
值得注意的是,与实体的主要标识符不同,自然 ID 可能是可变的。
现在,我们必须考虑一个微妙之处,当我们必须处理所谓的“参考数据”时,通常会出现这种微妙之处,即容易装入内存且不会发生太大变化的数据。
7.9。缓存和关联获取
让我们再考虑一下我们的Publisher班级:
@Cache(usage=NONSTRICT_READ_WRITE, region="Publishers")
@Entity
class Publisher { ... }有关出版商的数据并不经常变化,而且数量也不多。假设我们已经完成所有设置,以便发布者几乎始终在二级缓存中可用。
那么在这种情况下我们需要仔细考虑 type 的关联Publisher。
@ManyToOne
Publisher publisher;不需要延迟获取此关联,因为我们希望它在内存中可用,因此我们不会设置它fetch=LAZY。但另一方面,如果我们将其标记为急切获取,那么默认情况下,Hibernate 通常会使用连接来获取它。这给数据库带来了完全不必要的负载。
解决办法是@Fetch注释:
@ManyToOne @Fetch(SELECT)
Publisher publisher;By annotating the association @Fetch(SELECT), we suppress join fetching, giving Hibernate a chance to find the associated Publisher in the cache.
Therefore, we arrive at this rule of thumb:
Many-to-one associations to "reference data", or to any other data that will almost always be available in the cache, should be mapped EAGER,SELECT.Other associations, as we’ve already made clear, should be LAZY. | |
|---|---|
Once we’ve marked an entity or collection as eligible for storage in the second-level cache, we still need to set up an actual cache.
7.10. Configuring the second-level cache provider
Configuring a second-level cache provider is a rather involved topic, and quite outside the scope of this document. But in case it helps, we often test Hibernate with the following configuration, which uses EHCache as the cache implementation, as above in Optional dependencies:
| Configuration property name | Property value |
|---|---|
hibernate.cache.region.factory_class | jcache |
hibernate.javax.cache.uri | /ehcache.xml |
If you’re using EHCache, you’ll also need to include an ehcache.xml file that explicitly configures the behavior of each cache region belonging to your entities and collections. You’ll find more information about configuring EHCache here.
We may use any other implementation of JCache, such as Caffeine. JCache automatically selects whichever implementation it finds on the classpath. If there are multiple implementations on the classpath, we must disambiguate using:
| Configuration property name | Property value |
|---|---|
hibernate.javax.cache.provider | The implementation of javax.cache.spiCachingProvider, for example:org.ehcache.jsr107.EhcacheCachingProviderfor EHCachecom.github.benmanes.caffeine.jcache.spi.CaffeineCachingProviderfor Caffeine |
Alternatively, to use Infinispan as the cache implementation, the following settings are required:
| Configuration property name | Property value |
|---|---|
hibernate.cache.region.factory_class | infinispan |
hibernate.cache.infinispan.cfg | Path to infinispan configuration file, for example:org/infinispan/hibernate/cache/commons/builder/infinispan-configs.xmlfor a distributed cacheorg/infinispan/hibernate/cache/commons/builder/infinispan-configs-local.xmlto test with local cache |
Infinispan is usually used when distributed caching is required. There’s more about using Infinispan with Hibernate here.
Finally, there’s a way to globally disable the second-level cache:
| Configuration property name | Property value |
|---|---|
hibernate.cache.use_second_level_cache | true to enable caching, or false to disable it |
When hibernate.cache.region.factory_class is set, this property defaults to true.
| This setting lets us easily disable the second-level cache completely when troubleshooting or profiling performance. | |
|---|---|
You can find much more information about the second-level cache in the User Guide.
7.11. Caching query result sets
The caches we’ve described above are only used to optimize lookups by id or by natural id. Hibernate also has a way to cache the result sets of queries, though this is only rarely an efficient thing to do.
The query cache must be enabled explicitly:
| Configuration property name | Property value |
|---|---|
hibernate.cache.use_query_cache | true to enable the query cache |
To cache the results of a query, call SelectionQuery.setCacheable(true):
session.createQuery("from Product where discontinued = false")
.setCacheable(true)
.getResultList();默认情况下,查询结果集存储在名为 的缓存区域中default-query-results-region。由于不同的查询应该有不同的缓存策略,因此通常显式指定区域名称:
session.createQuery("from Product where discontinued = false")
.setCacheable(true)
.setCacheRegion("ProductCatalog")
.getResultList();结果集与逻辑时间戳一起缓存。通过“逻辑”,我们的意思是它实际上并不随时间线性增加,特别是它不是系统时间。
当 aProduct更新时,Hibernate不会遍历查询缓存,并使受更改影响的每个缓存结果集失效。相反,缓存中有一个特殊区域,其中保存每个表的最新更新的逻辑时间戳。这称为更新时间戳缓存,它保存在该区域中default-update-timestamps-region。
| 您有责任确保此缓存区域配置了适当的策略。特别是,更新时间戳永远不应该过期或被驱逐。 | |
|---|---|
当从缓存中读取查询结果集时,Hibernate 会将其时间戳与影响查询结果的每个表的时间戳进行比较,并且仅在结果集未过时的情况下才返回结果集。如果结果集已过时,Hibernate 会继续对数据库重新执行查询并更新缓存的结果集。
与任何二级缓存的通常情况一样,查询缓存可能会破坏事务的 ACID 属性。
7.12. 二级缓存管理
在大多数情况下,二级缓存是透明的。与 Hibernate 会话交互的程序逻辑不知道缓存,并且不受缓存策略更改的影响。
在最坏的情况下,与缓存的交互可以通过指定显式来控制CacheMode:
session.setCacheMode(CacheMode.IGNORE);或者,使用 JPA 标准 API:
entityManager.setCacheRetrieveMode(CacheRetrieveMode.BYPASS);
entityManager.setCacheStoreMode(CacheStoreMode.BYPASS);JPA 定义的缓存模式有两种类型:CacheRetrieveMode和CacheStoreMode。
| 模式 | 解释 |
|---|---|
CacheRetrieveMode.USE | 从缓存中读取数据(如果有) |
CacheRetrieveMode.BYPASS | 不从缓存中读取数据;直接进入数据库 |
CacheRetrieveMode.BYPASS如果我们担心从缓存中读取过时数据的可能性,我们可能会选择。
| 模式 | 解释 |
|---|---|
CacheStoreMode.USE | 从数据库读取或修改时将数据写入缓存;读取时不更新已缓存的项目 |
CacheStoreMode.REFRESH | 从数据库读取或修改时将数据写入缓存;读取时始终更新缓存的项目 |
CacheStoreMode.BYPASS | 不向缓存写入数据 |
我们应该选择CacheStoreMode.BYPASS是否要查询不需要缓存的数据。
最好在运行查询之前将其设置为,CacheStoreMode该BYPASS查询将返回一个包含我们预计不会很快再次需要的数据的大型结果集。这样可以节省工作量,并防止新读取的数据推出之前缓存的数据。 | |
|---|---|
在 JPA 中我们会使用这个习惯用法:
entityManager.setCacheStoreMode(CacheStoreMode.BYPASS);
List<Publisher> allpubs =
entityManager.createQuery("from Publisher", Publisher.class)
.getResultList();
entityManager.setCacheStoreMode(CacheStoreMode.USE);但 Hibernate 有更好的方法:
List<Publisher> allpubs =
session.createSelectionQuery("from Publisher", Publisher.class)
.setCacheStoreMode(CacheStoreMode.BYPASS)
.getResultList();HibernateCacheMode将CacheRetrieveModea 与CacheStoreMode.
休眠CacheMode | 等效的 JPA 模式 |
|---|---|
NORMAL | CacheRetrieveMode.USE,CacheStoreMode.USE |
IGNORE | CacheRetrieveMode.BYPASS,CacheStoreMode.BYPASS |
GET | CacheRetrieveMode.USE,CacheStoreMode.BYPASS |
PUT | CacheRetrieveMode.BYPASS,CacheStoreMode.USE |
REFRESH | CacheRetrieveMode.REFRESH,CacheStoreMode.BYPASS |
没有什么特别的理由CacheMode比 JPA 等价物更喜欢 Hibernate。这个枚举之所以存在只是因为 Hibernate 在被添加到 JPA 之前很久就已经有了缓存模式。
对于“参考”数据,即期望始终在二级缓存中找到的数据,最好在启动时填充缓存。EntityManager有一个非常简单的方法可以做到这一点:只需在获取or后立即执行查询 SessionFactory。SessionFactory sessionFactory = setupHibernate(new Configuration()) .buildSessionFactory(); // prime the second-level cache sessionFactory.inSession(session -> { session.createSelectionQuery("from Country")) .setReadOnly(true) .getResultList(); session.createSelectionQuery("from Product where discontinued = false")) .setReadOnly(true) .getResultList(); }); | |
|---|---|
有时,显式控制缓存是必要的或有利的,例如,驱逐一些我们知道过时的数据。该Cache接口允许以编程方式逐出缓存的项目。
sessionFactory.getCache().evictEntityData(Book.class, bookId);通过接口进行的二级缓存管理Cache不是事务感知的。所有操作都不Cache尊重与底层缓存关联的任何隔离或事务语义。特别是,通过该接口的方法进行驱逐会导致在任何当前事务和/或锁定方案之外立即“硬”删除。 | |
|---|---|
然而,通常情况下,Hibernate会在修改后自动驱逐或更新缓存数据,此外,根据配置的策略,未使用的缓存数据最终将过期。
这与一级缓存的情况完全不同。
7.13。会话缓存管理
当不再需要实体实例时,它们不会自动从会话缓存中逐出。相反,它们会保留在内存中,直到它们所属的会话被您的程序丢弃。
这些方法detach()允许clear()您从会话缓存中删除实体,使它们可用于垃圾回收。由于大多数会话的持续时间相当短暂,因此您不会经常需要这些操作。如果您发现自己认为在某种情况下*确实需要它们,那么您应该强烈考虑替代解决方案:*无状态会话。
7.14。无状态会话
Hibernate 的一个可能被低估的功能是StatelessSession界面,它提供了一种面向命令的、更裸机的方法来与数据库交互。
您可以从以下位置获得无状态会话SessionFactory:
StatelessSession ss = getSessionFactory().openStatelessSession();无状态会话:
- 没有一级缓存(持久化上下文),也不与任何二级缓存交互,并且
- 不实现事务性后写或自动脏检查,因此所有操作在显式调用时都会立即执行。
对于无状态会话,我们始终使用分离的对象。因此,编程模型有点不同:
| 方法名称和参数 | 影响 |
|---|---|
get(Class, Object) | 获取一个分离的对象,给定其类型和 ID,通过执行select |
fetch(Object) | 获取分离对象的关联 |
refresh(Object) | 通过执行以下命令刷新分离对象的状态select |
insert(Object) | 立即insert将给定瞬态对象的状态存入数据库 |
update(Object) | 立即update显示数据库中给定分离对象的状态 |
delete(Object) | 立即delete从数据库中获取给定分离对象的状态 |
upsert(Object) | 立即insert或使用 SQL语句的update给定分离对象的状态merge into |
没有任何flush()操作,所以update()总是显式的。 | |
|---|---|
在某些情况下,这使得无状态会话更容易使用,但需要注意的是,无状态会话更容易受到数据别名效应的影响,因为很容易获得两个不同的 Java 对象,它们都代表数据库的同一行桌子。
如果我们fetch()在无状态会话中使用,我们可以很容易地获得代表同一数据库行的两个对象! | |
|---|---|
特别是,缺乏持久性上下文意味着我们可以安全地执行批量处理任务,而无需分配大量内存。使用 aStatelessSession可以减少调用的需要:
clear()或detach()执行一级缓存管理,以及setCacheMode()绕过与二级缓存的交互。
| 无状态会话可能很有用,但对于大型数据集的批量操作,Hibernate 不可能与存储过程竞争! | |
|---|---|
使用无状态会话时,您应该注意以下附加限制:
- 持久化操作永远不会级联到关联的实例,
@ManyToMany对关联和s的更改@ElementCollection不能持久化,并且- 通过无状态会话执行的操作绕过回调。
7.15。乐观锁和悲观锁
最后,我们上面没有提到的负载下行为的一个方面是行级数据争用。当许多事务尝试读取和更新相同的数据时,程序可能会因锁升级、死锁和锁获取超时错误而变得无响应。
Hibernate 中的数据并发有两种基本方法:
- 使用列的乐观锁定
@Version,以及 - 使用 SQL 语法(或等效语法)的数据库级悲观锁定
for update。
在 Hibernate 社区中,使用乐观锁定更为常见,而 Hibernate 使这变得异常简单*。*
| 在可能的情况下,在多用户系统中,避免在用户交互过程中持有悲观锁。事实上,通常的做法是避免进行跨越用户交互的事务。对于多用户系统,乐观锁定才是王道。 | |
|---|---|
也就是说,悲观锁也有一席之地,它有时可以降低事务回滚的概率。
Therefore, the find(), lock(), and refresh() methods of the reactive session accept an optional LockMode. We can also specify a LockMode for a query. The lock mode can be used to request a pessimistic lock, or to customize the behavior of optimistic locking:
LockMode type | Meaning |
|---|---|
READ | An optimistic lock obtained implicitly whenever an entity is read from the database using select |
OPTIMISTIC | An optimistic lock obtained when an entity is read from the database, and verified using a select to check the version when the transaction completes |
OPTIMISTIC_FORCE_INCREMENT | An optimistic lock obtained when an entity is read from the database, and enforced using an update to increment the version when the transaction completes |
WRITE | A pessimistic lock obtained implicitly whenever an entity is written to the database using update or insert |
PESSIMISTIC_READ | A pessimistic for share lock |
PESSIMISTIC_WRITE | A pessimistic for update lock |
PESSIMISTIC_FORCE_INCREMENT | A pessimistic lock enforced using an immediate update to increment the version |
7.16. Collecting statistics
We may ask Hibernate to collect statistics about its activity by setting this configuration property:
| Configuration property name | Property value |
|---|---|
hibernate.generate_statistics | true to enable collection of statistics |
The statistics are exposed by the Statistics object:
long failedVersionChecks =
sessionFactory.getStatistics()
.getOptimisticFailureCount();
long publisherCacheMissCount =
sessionFactory.getStatistics()
.getEntityStatistics(Publisher.class.getName())
.getCacheMissCount()Hibernate’s statistics enable observability. Both Micrometer and SmallRye Metrics are capable of exposing these metrics.
7.17. Tracking down slow queries
When a poorly-performing SQL query is discovered in production, it can sometimes be hard to track down exactly where in the Java code the query originates. Hibernate offers two configuration properties that can make it easier to identify a slow query and find its source.
| Configuration property name | Purpose | Property value |
|---|---|---|
hibernate.log_slow_query | Log slow queries at the INFO level | The minimum execution time, in milliseconds, which characterizes a "slow" query |
hibernate.use_sql_comments | Prepend comments to the executed SQL | true or false |
When hibernate.use_sql_comments is enabled, the text of the HQL query is prepended as a comment to the generated SQL, which usually makes it easy to find the HQL in the Java code.
The comment text may be customized:
- by calling
Query.setComment(comment)orQuery.setHint(AvailableHints.HINT_COMMENT,comment), or - via the
@NamedQueryannotation.
| Once you’ve identified a slow query, one of the best ways to make it faster is to actually go and talk to someone who is an expert at making queries go fast. These people are called "database administrators", and if you’re reading this document you probably aren’t one. Database administrators know lots of stuff that Java developers don’t. So if you’re lucky enough to have a DBA about, you don’t need to Dunning-Kruger your way out of a slow query. | |
|---|---|
An expertly-defined index might be all you need to fix a slow query.
7.18. Adding indexes
The @Index annotation may be used to add an index to a table:
@Entity
@Table(indexes=@Index(columnList="title, year, publisher_id"))
class Book { ... }甚至可以指定索引列的顺序,或者索引应该不区分大小写:
@Entity
@Table(indexes=@Index(columnList="(lower(title)), year desc, publisher_id"))
class Book { ... }这使我们可以为特定查询创建自定义索引。
请注意,索引定义中的SQL 表达式lower(title)必须用括号括起来。columnList
目前尚不清楚有关索引的信息是否属于 Java 代码的注释。索引通常由数据库管理员维护和修改,最好由调优特定 RDBMS 性能的专家维护和修改。因此,最好将索引的定义保留在 DBA 可以轻松读取和修改的 SQL DDL 脚本中。 请记住,我们可以要求 Hibernate 使用该属性执行 DDL 脚本javax.persistence.schema-generation.create-script-source。 | |
|---|---|
7.19。处理非规范化数据
良好规范化模式中的典型关系数据库表具有相对较少的列数,因此通过有选择地查询列并仅填充实体类的某些字段几乎没有什么好处。
但偶尔,我们会听到有人询问如何映射具有一百列或更多列的表!在以下情况下可能会出现这种情况:
- 为了性能而故意对数据进行非规范化,
- 复杂分析查询的结果通过视图公开,或者
- 有人做了一些疯狂和错误的事情。
假设我们没有处理最后一种可能性。然后我们希望能够查询 Monster 表而不返回其所有列。乍一看,Hibernate 并没有为这个问题提供完美的解决方案。这种第一印象是具有误导性的。实际上,Hibernate 有不止一种方法来处理这种情况,真正的问题是在这些方法之间做出选择。我们可以:
- 将多个实体类映射到同一个表或视图,注意可变列映射到多个实体的“重叠”,
- 使用HQL或本机 SQL查询将结果返回到记录类型而不是检索实体实例,或者
- 使用字节码增强器并
@LazyGroup进行属性级延迟获取。
其他一些 ORM 解决方案将第三个选项推为处理大型表的推荐方式,但这从来都不是 Hibernate 团队或 Hibernate 社区的偏好。使用前两个选项之一的类型安全得多。
7.20。使用 Hibernate 进行响应式编程
最后,许多需要高可扩展性的系统现在都使用反应式编程和反应式流。 Hibernate Reactive将 O/R 映射带入反应式编程世界。您可以从其参考文档中了解有关 Hibernate Reactive 的更多信息。
| Hibernate Reactive 可以在同一程序中与普通 Hibernate 一起使用,并且可以重用相同的实体类。这意味着您可以在需要的地方使用反应式编程模型——也许只在系统中的一两个地方。您不需要使用反应流重写整个程序。 | |
|---|---|
8. 高级主题
在本引言的最后一章中,我们将讨论一些不属于引言的主题。在这里,我们考虑一些问题和解决方案,如果您是 Hibernate 新手,您可能不会立即遇到这些问题和解决方案。但我们确实希望您了解它们,以便到时候您就会知道该使用什么工具。
8.1. 过滤器
过滤器是 Hibernate 最好的和最未被充分利用的功能之一,我们为它们感到非常自豪。过滤器是对给定会话中可见数据的命名、全局定义、参数化限制。
明确定义的过滤器的示例可能包括:
- 根据行级权限限制给定用户可见的数据的过滤器,
- 隐藏已被软删除的数据的过滤器,
- 在版本化数据库中,显示过去某个给定时刻当前版本的过滤器,或者
- 限制与特定地理区域相关的数据的过滤器。
必须在某处声明过滤器。包描述符是一个与任何地方一样好的地方@FilterDef:
@FilterDef(name = "ByRegion",
parameters = @ParamDef(name = "region", type = String.class))
package org.hibernate.example;该过滤器有一个参数。原则上,更高级的过滤器可能有多个参数,尽管我们承认这种情况非常罕见。
如果您向包描述符添加注释,并且您正在使用它Configuration来配置 Hibernate,请确保您调用Configuration.addPackage()以让 Hibernate 知道包描述符已被注释。 | |
|---|---|
通常,但不一定,a@FilterDef指定默认限制:
@FilterDef(name = "ByRegion",
parameters = @ParamDef(name = "region", type = String.class),
defaultCondition = "region = :region")
package org.hibernate.example;限制必须包含对过滤器参数的引用,使用命名参数的常用语法指定。
任何受过滤器影响的实体或集合都必须进行注释@Filter:
@Entity
@Filter(name = example_.BY_REGION)
class User {
@Id String username;
String region;
...
}与往常一样,这里example_.BY_REGION是由元模型生成器生成的,并且只是一个值为 的常量"ByRegion"。
如果@Filter注释没有明确指定限制,则 给定的默认限制@FilterDef将应用于实体。但实体可以自由地覆盖默认条件。
@Entity
@Filter(name = example_.FILTER_BY_REGION, condition = "name = :region")
class Region {
@Id String name;
...
}condition请注意, or指定的限制defaultCondition是本机 SQL 表达式。
| 注解 | 目的 |
|---|---|
@FilterDef | 定义一个过滤器并声明其名称(每个过滤器只有一个) |
@Filter | 指定过滤器如何应用于给定实体或集合(每个过滤器有多个) |
By default, a new session comes with every filter disabled. A filter may be explicitly enabled in a given session by calling enableFilter() and assigning arguments to the parameters of the filter. You should do this right at the start of the session.
sessionFactory.inTransaction(session -> {
session.enableFilter(example_.FILTER_BY_REGION)
.setParameter("region", "es")
.validate();
...
});Now, any queries executed within the session will have the filter restriction applied. Collections annotated @Filter will also have their members correctly filtered.
On the other hand, filters are not applied to @ManyToOne associations, nor to find(). This is completely by design and is not in any way a bug. | |
|---|---|
More than one filter may be enabled in a given session.
When we only need to filter rows by a static condition with no parameters, we don’t need a filter, since @SQLRestriction provides a much simpler way to do that. | |
|---|---|
We’ve mentioned that a filter can be used to implement versioning, and to provide historical views of the data. Being such a general-purpose construct, filters provide a lot of flexibility here. But if you’re after a more focused/opinionated solution to this problem, you should definitely check out Envers.
Using Envers for auditing historical data
Envers is an add-on to Hibernate ORM which keeps a historical record of each versioned entity in a separate audit table, and allows past revisions of the data to be viewed and queried. A full introduction to Envers would require a whole chapter, so we’ll just give you a quick taste here.
First, we must mark an entity as versioned, using the @Audited annotation:
@Audited @Entity
@Table(name="CurrentDocument")
@AuditTable("DocumentRevision")
class Document { ... }The @AuditTable annotation is optional, and it’s better to set either org.hibernate.envers.audit_table_prefix or org.hibernate.envers.audit_table_suffix and let the audit table name be inferred. | |
|---|---|
The AuditReader interface exposes operations for retrieving and querying historical revisions. It’s really easy to get hold of one of these:
AuditReader reader = AuditReaderFactory.get(entityManager);Envers tracks revisions of the data via a global revision number. We may easily find the revision number which was current at a given instant:
Number revision = reader.getRevisionNumberForDate(datetime);We can use the revision number to ask for the version of our entity associated with the given revision number:
Document doc = reader.find(Document.class, id, revision);Alternatively, we can directly ask for the version which was current at a given instant:
Document doc = reader.find(Document.class, id, datetime);We can even execute queries to obtain lists of entities current at the given revision number:
List documents =
reader.createQuery()
.forEntitiesAtRevision(Document.class, revision)
.getResultList();For much more information, see the User Guide.
Another closely-related problem is multi-tenancy.
8.2. Multi-tenancy
A multi-tenant database is one where the data is segregated by tenant. We don’t need to actually define what a "tenant" really represents here; all we care about at this level of abstraction is that each tenant may be distinguished by a unique identifier. And that there’s a well-defined current tenant in each session.
我们可以在打开会话时指定当前租户:
var session =
sessionFactory.withOptions()
.tenantIdentifier(tenantId)
.openSession();或者,当使用 JPA 标准 API 时:
var entityManager =
entityManagerFactory.createEntityManager(Map.of(HibernateHints.HINT_TENANT_ID, tenantId));然而,由于我们通常无法对会话的创建进行这种级别的控制,因此更常见的是CurrentTenantIdentifierResolver向 Hibernate 提供 的实现。
实现多租户的常见方式有以下三种:
- 每个租户都有自己的数据库,
- 每个租户都有自己的模式,或者
- 租户在单个模式中共享表,并且行用租户 ID 标记。
从 Hibernate 的角度来看,前两个选项几乎没有什么区别。Hibernate 将需要获取一个 JDBC 连接,该连接具有对当前租户拥有的数据库和架构的权限。
因此,我们必须实现一个MultiTenantConnectionProvider承担这个责任的:
- 有时,Hibernate 会请求一个连接,并传递当前租户的 id,然后我们必须创建一个合适的连接或从池中获取一个连接,并将其返回给 Hibernate,并且
- 之后,Hibernate会释放该连接并要求我们销毁它或将其返回到适当的池中。
查看DataSourceBasedMultiTenantConnectionProviderImpl灵感。 | |
|---|---|
第三个选项则完全不同。在本例中,我们不需要 a MultiTenantConnectionProvider,但我们需要一个专用列来保存每个实体映射的租户 ID。
@Entity
class Account {
@Id String id;
@TenantId String tenantId;
...
}该@TenantId注释用于指示保存租户id的实体的属性。在给定的会话中,我们的数据会自动过滤,以便只有标记有当前租户的租户 ID 的行在该会话中可见。
| 原生 SQL 查询不会自动按租户 id 过滤;你必须自己做那部分。 | |
|---|---|
要利用多租户,我们通常需要至少设置以下配置属性之一:
| 配置属性名称 | 目的 |
|---|---|
hibernate.tenant_identifier_resolver | 指定CurrentTenantIdentifierResolver |
hibernate.multi_tenant_connection_provider | 指定MultiTenantConnectionProvider |
8.3. 使用自定义编写的 SQL
我们已经讨论了如何运行用 SQL 编写的查询,但有时这还不够。有时(但比您预期的要少得多)我们希望自定义 Hibernate 使用的 SQL 来对实体或集合执行基本的 CRUD 操作。
为此,我们可以使用@SQLInsert和朋友:
@Entity
@SQLInsert(sql = "insert into person (name, id, valid) values (?, ?, true)", check = COUNT)
@SQLUpdate(sql = "update person set name = ? where id = ?")
@SQLDelete(sql = "update person set valid = false where id = ?")
@SQLSelect(sql = "select id, name from person where id = ? and valid = true")
public static class Person { ... }如果自定义 SQL 应通过 a 执行CallableStatement,只需指定callable=true。 | |
|---|---|
由这些注释之一指定的任何 SQL 语句都必须具有 Hibernate 期望的 JDBC 参数数量,即实体映射的每一列都有一个参数,并且按照 Hibernate 期望的顺序。特别是,主键列必须放在最后。
然而,@Column注释确实在这里提供了一些灵活性:
- 如果某个列不应作为自定义
insert语句的一部分编写,并且在自定义 SQL 中没有相应的 JDBC 参数,则将其映射@Column(insertable=false),或 - 如果某个列不应作为自定义
update语句的一部分编写,并且在自定义 SQL 中没有相应的 JDBC 参数,则将其映射@Column(updatable=false)。
如果您需要自定义 SQL,但目标是 SQL 的多种方言,则可以使用 中定义的注释DialectOverrides。例如,此注释允许我们覆盖insert仅适用于 PostgreSQL 的自定义语句:@DialectOverride.SQLInsert(dialect = PostgreSQLDialect.class, override = @SQLInsert(sql="insert into person (name,id) values (?,gen_random_uuid())"))甚至可以覆盖特定版本数据库的自定义 SQL。 | |
|---|---|
有时,自定义insert或update语句会向映射列分配一个值,该值是在数据库上执行该语句时计算的。例如,可以通过调用 SQL 函数来获取该值:
@SQLInsert(sql = "insert into person (name, id) values (?, gen_random_uuid())")但表示正在插入或更新的行的实体实例不会自动填充该值。因此我们的持久性上下文失去了与数据库的同步。在这种情况下,我们可以使用注释来告诉 Hibernate 在每个或@Generated之后重新读取实体的状态。insert``update
8.4. 处理数据库生成的列
有时,列值是由数据库中发生的事件分配或改变的,并且对 Hibernate 不可见。例如:
- 表可能具有由触发器填充的列值,
- 映射列可能具有在 DDL 中定义的默认值,或者
- 正如我们在上一小节中看到的,自定义 SQL
insert或update语句可能会为映射列分配一个值。
处理这种情况的一种方法是refresh()在适当的时刻显式调用,强制会话重新读取实体的状态。但这很烦人。
该@Generated注释减轻了我们显式调用的负担refresh()。它指定带注释的实体属性的值由数据库生成,并且生成的值应该使用 SQL 子句自动检索returning,或者select在生成后单独检索。
一个有用的示例是以下映射:
@Entity
class Entity {
@Generated @Id
@ColumnDefault("gen_random_uuid()")
UUID id;
}生成的DDL为:
create table Entity (
id uuid default gen_random_uuid() not null,
primary key (uuid)
)所以这里 的值id是通过调用 PostgreSQL 函数 ,由列 default 子句定义的gen_random_uuid()。
当更新期间生成列值时,请使用@Generated(event=UPDATE)。当插入和更新都生成值时,请使用@Generated(event={INSERT,UPDATE})。
对于应该使用 SQLgenerated always as子句生成的列,最好使用@GeneratedColumn注释,以便 Hibernate 自动生成正确的 DDL。 | |
|---|---|
实际上,@Generated和@GeneratedColumn注释是根据更通用且用户可扩展的框架来定义的,用于处理 Java 或数据库生成的属性值。那么让我们放下一层,看看它是如何工作的。
8.5. 用户定义的生成器
JPA 没有定义扩展 id 生成策略集的标准方法,但 Hibernate 定义了:
Generator包中接口的层次结构允许org.hibernate.generator您定义新的生成器,并且@IdGeneratorType包中的元注释允许org.hibernate.annotations您编写将类型与标识符属性关联起来的注释Generator。
此外,元注释允许您编写将类型与非属性@ValueGenerationType相关联的注释。Generator``@Id
这些 API 是 Hibernate 6 中的新 API,取代了旧版本 Hibernate 中的经典IdentifierGenerator接口和注释。@GenericGenerator然而,旧的 API 仍然可用,并且IdentifierGenerator为旧版本的 Hibernate 编写的自定义在 Hibernate 6 中继续工作。 | |
|---|---|
Hibernate 有一系列内置生成器,它们是根据这个新框架定义的。
| 注解 | 执行 | 目的 |
|---|---|---|
@Generated | GeneratedGeneration | 一般处理数据库生成的值 |
@GeneratedColumn | GeneratedAlwaysGeneration | 处理使用生成的值generated always |
@CurrentTimestamp | CurrentTimestampGeneration | 对数据库或内存中创建或更新时间戳的生成的通用支持 |
@CreationTimestamp | CurrentTimestampGeneration | 实体首次持久化时生成的时间戳 |
@UpdateTimestamp | CurrentTimestampGeneration | 使实体持久化时生成的时间戳,并在每次修改实体时重新生成 |
@UuidGenerator | UuidGenerator | 更灵活的 RFC 4122 UUID 生成器 |
此外,该框架还定义了对 JPA 标准 id 生成策略的支持。
举个例子,让我们看看它@UuidGenerator是如何定义的:
@IdGeneratorType(org.hibernate.id.uuid.UuidGenerator.class)
@ValueGenerationType(generatedBy = org.hibernate.id.uuid.UuidGenerator.class)
@Retention(RUNTIME)
@Target({ FIELD, METHOD })
public @interface UuidGenerator { ... }@UuidGenerator都是元注释的@IdGeneratorType,@ValueGenerationType因为它可以用于生成常规属性的 id 和值。不管怎样,这个Generator类都做了艰苦的工作:
public class UuidGenerator
// this generator produced values before SQL is executed
implements BeforeExecutionGenerator {
// constructors accept an instance of the @UuidGenerator
// annotation, allowing the generator to be "configured"
// called to create an id generator
public UuidGenerator(
org.hibernate.annotations.UuidGenerator config,
Member idMember,
CustomIdGeneratorCreationContext creationContext) {
this(config, idMember);
}
// called to create a generator for a regular attribute
public UuidGenerator(
org.hibernate.annotations.UuidGenerator config,
Member member,
GeneratorCreationContext creationContext) {
this(config, idMember);
}
...
@Override
public EnumSet<EventType> getEventTypes() {
// UUIDs are only assigned on insert, and never regenerated
return INSERT_ONLY;
}
@Override
public Object generate(SharedSessionContractImplementor session, Object owner, Object currentValue, EventType eventType) {
// actually generate a UUID and transform it to the required type
return valueTransformer.transform( generator.generateUuid( session ) );
}
}@IdGeneratorType您可以从 for和 for的 Javadoc 中找到有关自定义生成器的更多信息org.hibernate.generator。
8.6. 命名策略
当使用预先存在的关系模式时,通常会发现模式中使用的列和表命名约定与 Java 的命名约定不匹配。
当然,@Table和@Column注释让我们显式指定映射的表或列名。但我们希望避免将这些注释分散在整个领域模型中。
因此,Hibernate 让我们定义 Java 命名约定和关系模式命名约定之间的映射。这种映射称为命名策略。
首先,我们需要了解 Hibernate 如何分配和处理名称。
- 逻辑命名是应用命名规则来确定O/R 映射中未显式分配名称的对象的逻辑名称的过程。也就是说,当没有
@Table或@Column注释时。 - 物理命名是应用附加规则将逻辑名称转换为将在数据库中使用的实际“物理”名称的过程。例如,规则可能包括使用标准化缩写或修剪标识符的长度等内容。
因此,有两种命名策略,其职责略有不同。Hibernate 附带了这些接口的默认实现:
| 味道 | 默认实现 |
|---|---|
当注释未指定逻辑名称时, AnImplicitNamingStrategy负责分配逻辑名称 | 实现 JPA 定义的规则的默认策略 |
APhysicalNamingStrategy负责转换逻辑名称并生成数据库中使用的名称 | 不进行任何处理的简单实现 |
我们碰巧不太喜欢 JPA 定义的命名规则,它指定混合大小写和驼峰式大小写标识符应使用下划线连接。我们打赌您可以轻松想出ImplicitNamingStrategy比这更好的方法!(提示:它应该始终生成合法的混合大小写标识符。) | |
|---|---|
流行的PhysicalNamingStrategy产品是蛇形识别器。 | |
|---|---|
可以使用我们在最小化重复映射信息中已经提到的配置属性来启用自定义命名策略,而无需太多解释。
| 配置属性名称 | 目的 |
|---|---|
hibernate.implicit_naming_strategy | 指定ImplicitNamingStrategy |
hibernate.physical_naming_strategy | 指定PhysicalNamingStrategy |
8.7. 空间数据类型
Hibernate Spatial通过一组OGC空间类型的 Java 映射增强了内置基本类型。
- Geolatte-geom定义了一组实现 OGC 空间类型的 Java 类型,以及用于在数据库本机空间数据类型之间进行转换的编解码器。
- Hibernate Spatial 本身提供与 Hibernate 的集成。
要使用 Hibernate Spatial,我们必须将其添加为依赖项,如可选依赖项中所述。
然后我们可以立即在我们的实体中使用 Geolatte-geom 和 JTS 类型。不需要特殊注释:
import org.locationtech.jts.geom.Point;
import jakarta.persistence.*;
@Entity
class Event {
Event() {}
Event(String name, Point location) {
this.name = name;
this.location = location;
}
@Id @GeneratedValue
Long id;
String name;
Point location;
}生成的 DDL 使用geometry映射的列的类型location:
create table Event (
id bigint not null,
location geometry,
name varchar(255),
primary key (id)
)Hibernate Spatial 允许我们使用空间类型,就像使用任何内置的基本属性类型一样。
var geometryFactory = new GeometryFactory();
...
Point point = geometryFactory.createPoint(new Coordinate(10, 5));
session.persist(new Event("Hibernate ORM presentation", point));但它的强大之处在于我们可以编写一些涉及空间类型函数的非常奇特的查询:
Polygon triangle =
geometryFactory.createPolygon(
new Coordinate[] {
new Coordinate(9, 4),
new Coordinate(11, 4),
new Coordinate(11, 20),
new Coordinate(9, 4)
}
);
Point event =
session.createQuery("select location from Event where within(location, :zone) = true", Point.class)
.setParameter("zone", triangle)
.getSingleResult();这里,within()是 OpenGIS 规范定义的测试空间关系的函数之一。其他此类函数包括touches()、intersects()、distance()、boundary()等。并非每个数据库都支持所有空间关系函数。空间关系函数的支持矩阵可以在用户指南中找到。
如果你想在 H2 上使用空间函数,请先运行以下代码:sessionFactory.inTransaction(session -> { session.doWork(connection -> { try (var statement = connection.createStatement()) { statement.execute("create alias if not exists h2gis_spatial for \"org.h2gis.functions.factory.H2GISFunctions.load\""); statement.execute("call h2gis_spatial()"); } }); } ); | |
|---|---|
8.8. 有序和排序的集合和映射键
Java 列表和映射不能很自然地映射到表之间的外键关系,因此我们倾向于避免使用它们来表示实体类之间的关联。但是,如果您觉得确实需要一个比 更精美结构的集合Set,Hibernate 确实有选择。
前三个选项让我们将 a 的索引List或 a 的键映射Map到列,并且通常与@ElementCollection, 或 在关联的拥有方一起使用:
| 注解 | 目的 | JPA标准 |
|---|---|---|
@OrderColumn | 指定用于维护列表顺序的列 | ✔ |
@ListIndexBase | 列表第一个元素的列值(默认为零) | ✖ |
@MapKeyColumn | 指定用于持久化映射键的列(当键为基本类型时使用) | ✔ |
@MapKeyJoinColumn | 指定用于保存映射键的列(当键是实体时使用) | ✔ |
@ManyToMany
@OrderColumn // order of list is persistent
List<Author> authors = new ArrayList<>();
@ElementCollection
@OrderColumn(name="tag_order") @ListIndexBase(1) // order column and base value
List<String> tags;
@ElementCollection
@CollectionTable(name = "author_bios", // table name
joinColumns = @JoinColumn(name = "book_isbn")) // column holding foreign key of owner
@Column(name="bio") // column holding map values
@MapKeyJoinColumn(name="author_ssn") // column holding map keys
Map<Author,String> biographies;对于Map表示无主@OneToMany关联的 a,该列还必须映射到拥有方,通常是通过目标实体的属性。在这种情况下,我们通常使用不同的注释:
| 注解 | 目的 | JPA标准 |
|---|---|---|
@MapKey | 指定作为映射键的目标实体的属性 | ✔ |
@OneToMany(mappedBy = Book_.PUBLISHER)
@MapKey(name = Book_.TITLE) // the key of the map is the title of the book
Map<String,Book> booksByTitle = new HashMap<>();现在,让我们介绍一点区别:
- 有序集合是在数据库中维护排序的集合,并且
- 排序集合是在 Java 代码中排序的集合。
这些注释允许我们指定从数据库读取集合元素时应如何排序:
| 注解 | 目的 | JPA标准 |
|---|---|---|
@OrderBy | 指定用于对集合进行排序的 JPQL 片段 | ✔ |
@SQLOrder | 指定用于对集合进行排序的 SQL 片段 | ✖ |
另一方面,以下注释指定集合应如何在内存中排序,并用于SortedSet或类型的集合SortedMap:
| 注解 | 目的 | JPA标准 |
|---|---|---|
@SortNatural | 指定集合的元素是Comparable | ✖ |
@SortComparator | 指定Comparator用于对集合进行排序的 | ✖ |
在幕后,Hibernate 使用TreeSet或TreeMap来按排序顺序维护集合。
8.9. 任何映射
映射@Any是一种多态多对一关联,其中目标实体类型不通过通常的实体继承相关。使用存储在关系的引用侧的鉴别器值来区分目标类型。
这与判别式继承完全不同,判别器保留在由引用的实体层次结构映射的表中。
例如,考虑一个Order包含信息的实体Payment,其中 aPayment可能是 aCashPayment或 a CreditCardPayment:
interface Payment { ... }
@Entity
class CashPayment { ... }
@Entity
class CreditCardPayment { ... }在这个例子中,Payment没有被声明为实体类型,并且没有被注释@Entity。CashPayment它甚至可能是和的一个接口,或者至多只是一个映射的超类CreditCardPayment。因此就对象/关系映射而言,CashPayment并且CreditCardPayment不会被认为参与相同的实体继承层次结构。
另一方面,CashPayment和CreditCardPayment确实具有相同的标识符类型。这个很重要。
映射@Any将存储标识具体类型的鉴别器值Payment以及关联的状态Order,而不是将其存储在由 映射的表中Payment。
@Entity
class Order {
...
@Any
@AnyKeyJavaClass(UUID.class) //the foreign key type
@JoinColumn(name="payment_id") // the foreign key column
@Column(name="payment_type") // the discriminator column
// map from discriminator values to target entity types
@AnyDiscriminatorValue(discriminator="CASH", entity=CashPayment.class)
@AnyDiscriminatorValue(discriminator="CREDIT", entity=CreditCardPayment.class)
Payment payment;
...
}@Any将映射中的“外键”视为由外键和鉴别器一起组成的复合值是合理的。但请注意,此复合外键只是概念性的,不能声明为关系数据库表上的物理约束。
有许多注释可用于表达这种复杂且不自然的映射:
| 注释 | 目的 |
|---|---|
@Any | 声明属性是可区分的多态关联映射 |
@AnyDiscriminator | 指定鉴别器的Java类型 |
@JdbcType或者@JdbcTypeCode | 指定鉴别器的 JDBC 类型 |
@AnyDiscriminatorValue | 指定鉴别器值如何映射到实体类型 |
@Column或者@Formula | 指定存储鉴别器值的列或公式 |
@AnyKeyJavaType或者@AnyKeyJavaClass | 指定外键的 Java 类型(即目标实体的 id) |
@AnyKeyJdbcType或者@AnyKeyJdbcTypeCode | 指定外键的 JDBC 类型 |
@JoinColumn | 指定外键列 |
当然,@Any映射是不受欢迎的,除非在极其特殊的情况下,因为在数据库级别强制执行引用完整性要困难得多。
目前,在 HQL 中查询关联还存在一些限制@Any。这是允许的:
from Order ord
join CashPayment cash
on id(ord.payment) = cash.id@Any当前尚未实现映射的多态关联连接。 | |
|---|---|
8.10. 插入和更新中的选择性列列表
默认情况下,Hibernate 在 boostrap 期间为每个实体生成insert和语句,并且每次使实体的实例持久化时update重用相同的语句,每次修改实体的实例时重用相同的语句。insert``update
这意味着:
- 如果一个属性是
null当实体被持久化时,它的映射列被冗余地包含在 SQL 中insert,并且 - 更糟糕的是,如果某个属性在其他属性更改时未修改,则该属性映射的列将被冗余地包含在 SQL 中
update。
大多数时候,这并不是一个值得担心的问题。与数据库交互的成本通常由往返成本决定,而不是由 或 中的列数insert决定update。但在它确实变得重要的情况下,有两种方法可以更好地选择 SQL 中包含哪些列。
JPA 标准方法是通过@Column注释静态地指示哪些列符合包含条件。例如,如果一个实体总是使用 immutablecreationDate和 no创建completionDate,那么我们会写:
@Column(updatable=false) LocalDate creationDate;
@Column(insertable=false) LocalDate completionDate;This approach works quite well in many cases, but often breaks down for entities with more than a handful of updatable columns.
An alternative solution is to ask Hibernate to generate SQL dynamically each time an insert or update is executed. We do this by annotating the entity class.
| Annotation | Purpose |
|---|---|
@DynamicInsert | Specifies that an insert statement should be generated each time an entity is made persistent |
@DynamicUpdate | Specifies that an update statement should be generated each time an entity is modified |
It’s important to realize that, while @DynamicInsert has no impact on semantics, the more useful @DynamicUpdate annotation does have a subtle side effect.
The wrinkle is that if an entity has no version property, @DynamicUpdate opens the possibility of two optimistic transactions concurrently reading and selectively updating a given instance of the entity. In principle, this might lead to a row with inconsistent column values after both optimistic transactions commit successfully. | |
|---|---|
Of course, this consideration doesn’t arise for entities with a @Version attribute.
But there’s a solution! Well-designed relational schemas should have constraints to ensure data integrity. That’s true no matter what measures we take to preserve integrity in our program logic. We may ask Hibernate to add a check constraint to our table using the @Check annotation. Check constraints and foreign key constraints can help ensure that a row never contains inconsistent column values. | |
|---|---|
8.11. Using the bytecode enhancer
Hibernate’s bytecode enhancer enables the following features:
- attribute-level lazy fetching for basic attributes annotated
@Basic(fetch=LAZY)and for lazy non-polymorphic associations, - interception-based—instead of the usual snapshot-based—detection of modifications.
To use the bytecode enhancer, we must add the Hibernate plugin to our gradle build:
plugins {
id "org.hibernate.orm" version "6.3.0.Final"
}
hibernate { enhancement }Consider this field:
@Entity
class Book {
...
@Basic(optional = false, fetch = LAZY)
@Column(length = LONG32)
String fullText;
...
}The fullText field maps to a clob or text column, depending on the SQL dialect. Since it’s expensive to retrieve the full book-length text, we’ve mapped the field fetch=LAZY, telling Hibernate not to read the field until it’s actually used.
- Without the bytecode enhancer, this instruction is ignored, and the field is always fetched immediately, as part of the initial
selectthat retrieves theBookentity. - With bytecode enhancement, Hibernate is able to detect access to the field, and lazy fetching is possible.
By default, Hibernate fetches all lazy fields of a given entity at once, in a single select, when any one of them is accessed. Using the @LazyGroup annotation, it’s possible to assign fields to distinct "fetch groups", so that different lazy fields may be fetched independently. | |
|---|---|
Similarly, interception lets us implement lazy fetching for non-polymorphic associations without the need for a separate proxy object. However, if an association is polymorphic, that is, if the target entity type has subclasses, then a proxy is still required.
Interception-based change detection is a nice performance optimization with a slight cost in terms of correctness.
- Without the bytecode enhancer, Hibernate keeps a snapshot of the state of each entity after reading from or writing to the database. When the session flushes, the snapshot state is compared to the current state of the entity to determine if the entity has been modified. Maintaining these snapshots does have an impact on performance.
- With bytecode enhancement, we may avoid this cost by intercepting writes to the field and recording these modifications as they happen.
This optimization isn’t completely transparent, however.
Interception-based change detection is less accurate than snapshot-based dirty checking. For example, consider this attribute:byte[] image;Interception is able to detect writes to the image field, that is, replacement of the whole array. It’s not able to detect modifications made directly to the elements of the array, and so such modifications may be lost. | |
|---|---|
8.12. Named fetch profiles
We’ve already seen two different ways to override the default fetching strategy for an association:
- JPA entity graphs, and
- the
join fetchclause in HQL, or, equivalently, the methodFrom.fetch()in the criteria query API.
A third way is to define a named fetch profile. First, we must declare the profile, by annotating a class or package:
@FetchProfile(name = "EagerBook")
@Entity
class Book { ... }Note that even though we’ve placed this annotation on the Book entity, a fetch profile—unlike an entity graph—isn’t "rooted" at any particular entity.
We may specify association fetching strategies using the fetchOverrides member of the @FetchProfile annotation, but frankly it looks so messy that we’re embarrassed to show it to you here.
Similarly, a JPA entity graph may be defined using @NamedEntityGraph. But the format of this annotation is even worse than @FetchProfile(fetchOverrides=…), so we can’t recommend it. 💀 | |
|---|---|
A better way is to annotate an association with the fetch profiles it should be fetched in:
@FetchProfile(name = "EagerBook")
@Entity
class Book {
...
@ManyToOne(fetch = LAZY)
@FetchProfileOverride(profile = Book_.PROFILE_EAGER_BOOK, mode = JOIN)
Publisher publisher;
@ManyToMany
@FetchProfileOverride(profile = Book_.PROFILE_EAGER_BOOK, mode = JOIN)
Set<Author> authors;
...
}
@Entity
class Author {
...
@OneToOne
@FetchProfileOverride(profile = Book_.PROFILE_EAGER_BOOK, mode = JOIN)
Person person;
...
}Here, once again, Book_.PROFILE_EAGER_BOOK is generated by the Metamodel Generator, and is just a constant with the value "EagerBook".
For collections, we may even request subselect fetching:
@FetchProfile(name = "EagerBook")
@FetchProfile(name = "BookWithAuthorsBySubselect")
@Entity
class Book {
...
@OneToOne
@FetchProfileOverride(profile = Book_.PROFILE_EAGER_BOOK, mode = JOIN)
Person person;
@ManyToMany
@FetchProfileOverride(profile = Book_.PROFILE_EAGER_BOOK, mode = JOIN)
@FetchProfileOverride(profile = Book_.BOOK_WITH_AUTHORS_BY_SUBSELECT,
mode = SUBSELECT)
Set<Author> authors;
...
}我们可以根据需要定义任意多个不同的获取配置文件。
| 注解 | 目的 |
|---|---|
@FetchProfile | @FetchOverride声明一个命名的获取配置文件,可选地包括s列表 |
@FetchProfile.FetchOverride | 将获取策略覆盖声明为@FetchProfile声明的一部分 |
@FetchProfileOverride | 在给定的获取配置文件中指定带注释的关联的获取策略 |
必须为给定会话显式启用获取配置文件:
session.enableFetchProfile(Book_.PROFILE_EAGER_BOOK);
Book eagerBook = session.find(Book.class, bookId);那么为什么或何时我们可能更喜欢命名获取配置文件而不是实体图呢?嗯,确实很难说。很高兴有这个功能,如果您喜欢它,那就太好了。但 Hibernate 提供了我们认为大多数时候更具吸引力的替代方案。
获取配置文件的唯一优点是它们让我们非常有选择性地请求子选择获取。我们无法使用实体图做到这一点,也无法使用 HQL 做到这一点。
有一个名为 的特殊内置获取配置文件,它被定义为应用于每个 eager或关联的org.hibernate.defaultProfile配置文件。如果您启用此配置文件:@FetchProfileOverride(mode=JOIN)``@ManyToOne``@OneToOne``session.enableFetchProfile("org.hibernate.defaultProfile");然后,outer join此类关联的 s 将自动添加到每个 HQL 或条件查询中。如果您不想join fetch显式地输入这些 es,那么这很好。原则上,它甚至有助于部分缓解JPA为.fetch``@ManyToOne | |
|---|---|
9. 制作人员
这个版本是翻译版,可能存在错误,如有疑问,请对照查阅官方文档。
Hibernate ORM 贡献者的完整列表可以在GitHub 存储库中找到 。
以下贡献者参与了本文档的编写:
- 加文·金
版本 6.3.1.Final 最后更新时间 2023-09-19 09:14:42 UTC